Eine Anleitung in der statistischen Programmiersprache R
Autor:in
Patrik Häcki
Veröffentlichungsdatum
23. Mai 2026
Version
5.7
Einführung
Was ist R?
R ist eine kostenlose Open Source-Software für statistische Datenverarbeitung, die über die Website https://stat.ethz.ch/CRAN bezogen werden kann. Dabei umfasst R zum einen eine Vielzahl an Möglichkeiten zur Verarbeitung und Auswertung von Daten, die sich ohne grossen Aufwand nutzen lassen. Zum anderen kann man statistische Verfahren auch selbst programmieren und R fast beliebig erweitern. Von Anwendern erstellte Erweiterungen werden als Pakete oder packages bezeichnet und von ihren Programmierern oftmals für alle zugänglich gemacht. Im Comprehensive R Archive Network (kurz: CRAN), einem Netz aus Webservern, die Pakete und Code für R bereitstellen, sind eine Vielzahl solcher Pakete gelistet. Daneben wird auch Base R durch ein Kern-Team von Entwicklern ständig weiterentwickelt. R ist open-source, d.h. der Source Code ist unter der GNU Public License frei verfügbar.
Vorteile von R
Die wesentlichen Vorteile von R lassen sich insgesamt wie folgt zusammenfassen:
R kann kostenlos heruntergeladen und installiert werden.
R steht für Windows-, Unix- und Mac-Systeme zur Verfügung.
R wird von einem Kern-Team von Entwicklern ständig weiterentwickelt.
Es gibt eine Vielzahl von frei zugänglichen Erweiterungen, die von der kontinuierlich wachsenden R-Community erstellt werden.
R kann durch den Nutzer selbst erweitert werden.
Aufgrund dieser Vorteile findet R zunehmend Verbreitung und wird nicht nur im wissenschaftlichen Bereich, sondern auch für Anwendungen in der Wirtschaft eingesetzt.
Installation
R
Zentrale Anlaufstelle für den Download von R, für Zusatzpakete sowie für frei verfügbare Literatur ist die R-Projektseite https://www.r-project.org (in Englisch) oder das Comprehensive R Archive Network für die Schweiz https://stat.ethz.ch/CRAN, welches von der ETH Zürich betreut wird.
R-Editor
Anders als manche seiner kommerziellen und kostenpflichtigen Konkurrenten (wie etwa SPSS) kommt die freie Programmiersprache R ohne grafische Benutzeroberfläche daher. Nach dem Download und der Installation von R ist es deshalb empfehlenswert, zusätzlich einen komfortableren, kostenlosen R-Editor zu installieren.
RStudio von Posit (https://posit.co) ist die wohl am weitesten verbreitete integrierte Entwicklungsumgebung (IDE) für die Programmiersprache R. Weitere nützliche Editoren sind
R-Pakete sind Sammlungen von Funktionen und Werkzeugen, die von der R-Community entwickelt wurden. Sie erhöhen die Leistungsfähigkeit von R, indem sie bestehende Basisfunktionen verbessern oder neue Funktionen hinzufügen.
Mit der Funktion install.packages() werden neue Pakete installiert (z.B. das Paket janitor).
Für die Datenanalyse in sechs Schritten laden Sie bitte folgende Pakete in die aktuelle R-Session:
corrplot
ggdist
ggExtra
ggforce
ggstatsplot
glue
janitor
paletteer
palmerpenguins
patchwork
psych
RColorBrewer
readxl
recipes
rjson
scales
skimr
summarytools
statip
tidyAML
TidyDensity
tidyverse
treemap
Daten laden
Beispieldaten
In R stehen zahlreiche Import-Funktionen zur Verfügung, um Daten aus unterschiedlichen Anwendungen und in verschiedensten Formaten zu laden.
Zur Veranschaulichung der verschiedenen Funktionen und Visualisierungen werden die folgenden Datensätze verwendet:
Penguins
Die Daten wurden von Dr. Kristen Gorman und der Palmer Station, Antarctica LTER, gesammelt und von Allison Horst in ihrem R-Paket palmerpenguins popularisiert.
Die explorative Datenanalyse (Exploratory Data Analysis, abgekürzt EDA) ist ein wesentlicher Schritt in jedem Datenanalyseprojekt. Sie dient der Analyse und Untersuchung von Datensätzen und der deskriptiven Zusammenfassung ihrer wichtigsten Merkmale, wobei oft grafische Darstellungsmethoden verwendet werden. Mit Hilfe von Tabellen, Grafiken und der Ermittlung relevanter Kennzahlen wird versucht, einen Überblick über das gesamte Datenmaterial zu gewinnen, es zu ordnen und zusammenzufassen. Die EDA bildet damit die Grundlage für die weitere Analyse.
Objekte
Die Funktion ls() liefert eine Liste aller bisher gespeicherten Objekte wie Daten und Funktionen.
Code anzeigen
# Gespeicherte Objekte anzeigenls()
[1] "bgb_staat" "bgb_typ"
Mit der Funktion rm() werden alle unerwünschten Dateien gelöscht.
Code anzeigen
# Unerwünschte Dateien entfernenrm(bgb_typ)
Es ist auch möglich, alle Objekte auf einmal zu entfernen.
Code anzeigen
# Alle Objekte löschenrm(list =ls())
Datentypen
Ein Datensatz kann Merkmale unterschiedlicher Datentypen enthalten. Einige Daten können Zahlen sein (z.B. Alter oder Gewicht), während andere aus Text bestehen (wie Name oder Adresse). R kennt die folgenden Haupttypen:
Numerisch: Zahlen, einschliesslich Ganzzahlen (ganze Zahlen) und Dezimalzahlen
Mit der Funktion slice_head() werden die ersten Zeilen bzw. Beobachtungen ausgegeben. In diesem Beispiel wurde die Anzahl auf 10 festgelegt. Der Wert kann jedoch flexibel gewählt werden.
Code anzeigen
slice_head(.data = penguins, n =10)
# A tibble: 10 × 8
species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g
<fct> <fct> <dbl> <dbl> <int> <int>
1 Adelie Torgersen 39.1 18.7 181 3750
2 Adelie Torgersen 39.5 17.4 186 3800
3 Adelie Torgersen 40.3 18 195 3250
4 Adelie Torgersen NA NA NA NA
5 Adelie Torgersen 36.7 19.3 193 3450
6 Adelie Torgersen 39.3 20.6 190 3650
7 Adelie Torgersen 38.9 17.8 181 3625
8 Adelie Torgersen 39.2 19.6 195 4675
9 Adelie Torgersen 34.1 18.1 193 3475
10 Adelie Torgersen 42 20.2 190 4250
# ℹ 2 more variables: sex <fct>, year <int>
Die Funktion first() gibt das erste Element eines Eingabevektors zurück.
Code anzeigen
# Erstes Datenelement ausgebenfirst(x = penguins)
# A tibble: 1 × 8
species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g
<fct> <fct> <dbl> <dbl> <int> <int>
1 Adelie Torgersen 39.1 18.7 181 3750
# ℹ 2 more variables: sex <fct>, year <int>
Selbstverständlich ist es in R auch möglich, die letzten Zeilen eines Data Frames (dt. Datenrahmen) auszugeben. Die Funktion slice_tail() gibt die letzten n Zeilen eines Datenrahmens zurück (Standardwert ist 6).
Verwenden Sie slice_tail(1), um nur die letzte Zeile zu erhalten.
Code anzeigen
slice_tail(.data = penguins, n =1)
# A tibble: 1 × 8
species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g
<fct> <fct> <dbl> <dbl> <int> <int>
1 Chinstrap Dream 50.2 18.7 198 3775
# ℹ 2 more variables: sex <fct>, year <int>
Die Funktion last() ergänzt die Funktion first(), indem sie ebenfalls das letzte Element eines Vektors zurückgibt.
Code anzeigen
# Letztes Datenelement ausgebenlast(x = penguins)
# A tibble: 1 × 8
species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g
<fct> <fct> <dbl> <dbl> <int> <int>
1 Chinstrap Dream 50.2 18.7 198 3775
# ℹ 2 more variables: sex <fct>, year <int>
Mit der Funktion slice() von dplyr können bestimmte Zeilen ausgewählt werden. Um die vorletzte Zeile zu bekommen, verwenden Sie n() -1.
Code anzeigen
slice(.data = penguins, n() -1)
# A tibble: 1 × 8
species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g
<fct> <fct> <dbl> <dbl> <int> <int>
1 Chinstrap Dream 50.8 19 210 4100
# ℹ 2 more variables: sex <fct>, year <int>
Wenn Sie statt der ersten oder letzten Zeile eine zufällige Auswahl von Zeilen ausgeben möchten, steht Ihnen dafür die Funktion slice_sample() zur Verfügung.
Mit der Funktion nth() kann ein Vektorelement an einer beliebigen Stelle innerhalb des Vektors extrahiert werden. Durch Angabe des entsprechenden Elements erhalten Sie die gewünschte Ausgabe.
Code anzeigen
nth(x = penguins, n =7)
# A tibble: 1 × 8
species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g
<fct> <fct> <dbl> <dbl> <int> <int>
1 Adelie Torgersen 38.9 17.8 181 3625
# ℹ 2 more variables: sex <fct>, year <int>
Durch das Voranstellen eines Minuszeichens vor die Position lassen sich Elemente vom Ende des Vektors abrufen.
Code anzeigen
nth(x = penguins, n =-7)
# A tibble: 1 × 8
species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g
<fct> <fct> <dbl> <dbl> <int> <int>
1 Chinstrap Dream 46.8 16.5 189 3650
# ℹ 2 more variables: sex <fct>, year <int>
Die Funktion slice_max() des dplyr-Pakets ermöglicht eine intuitive Auswahl des maximalen Werts. Für den minimalen Wert steht slice_min() zur Verfügung.
Code anzeigen
slice_max(.data = penguins, order_by = bill_length_mm, n =5)
Der gesamte Datensatz kann mit der Funktion View() angezeigt werden. Die Darstellung ähnelt der von Microsoft Excel.
Code anzeigen
# Datensatz anzeigenView(penguins)
Während View() eine Excel-ähnliche Darstellung bietet, ermöglicht die Funktion fix() das Editieren von Datenzellen vergleichbar wie in Excel.
Code anzeigen
# Datenzellen editierenfix(penguins)
Mit glimpse() können Sie eine transponierte Version des Datenrahmens anzeigen, bei der die Spalten vertikal und die Daten horizontal dargestellt werden. glimpse() zeigt die Dimension des Datenrahmens und der zugrunde liegende Datentyp jedes Merkmals.
Code anzeigen
# Zusammenfassung der wichtigsten Kennzahlen in transponierter Formglimpse(penguins)
Alternativ kann die Struktur der Daten auch mit der Funktion str() ermittelt werden.
Code anzeigen
# Datenstruktur anzeigenstr(penguins)
'data.frame': 344 obs. of 8 variables:
$ species : Factor w/ 3 levels "Adelie","Chinstrap",..: 1 1 1 1 1 1 1 1 1 1 ...
$ island : Factor w/ 3 levels "Biscoe","Dream",..: 3 3 3 3 3 3 3 3 3 3 ...
$ bill_length_mm : num 39.1 39.5 40.3 NA 36.7 39.3 38.9 39.2 34.1 42 ...
$ bill_depth_mm : num 18.7 17.4 18 NA 19.3 20.6 17.8 19.6 18.1 20.2 ...
$ flipper_length_mm: num 181 186 195 NA 193 190 181 195 193 190 ...
$ body_mass_g : num 3750 3800 3250 NA 3450 ...
$ sex : Factor w/ 2 levels "female","male": 2 1 1 NA 1 2 1 2 NA NA ...
$ year : num 2007 2007 2007 2007 2007 ...
Masse der zentralen Tendenz
Um die Verteilung der Daten besser zu verstehen, können Sie die so genannten Masse der zentralen Tendenz untersuchen, welche statistisch die Mitte der Daten beschreibt. Ziel ist es, einen typischen Wert zu finden. Gängige Methoden zur Bestimmung der Datenmitte sind:
Mittelwert: Ein einfacher Durchschnittswert, der berechnet wird, indem alle Werte des Stichprobensatzes addiert und dann die Gesamtsumme durch die Anzahl der Stichproben dividiert wird.
Median: Der Wert, der in der Mitte des Bereichs aller Stichprobenwerte liegt.
Modus: Der am häufigsten vorkommende Wert in der Stichprobenmenge.
Code anzeigen
mean(penguins$body_mass_g, # Argument na.rm = TRUE ergänzen, um fehlende Werte für die Berechnung auszuschliessenna.rm =TRUE)
Mithilfe der Funktion colMeans() von Base R können die Mittelwerte mehrerer metrischer Vektoren gleichzeitig berechnet werden. Für die Zeilen gibt es die entsprechende Funktion rowMeans().
Schleifen sind grossartig, aber für sich wiederholende Aufgaben mit Datenstrukturen ist die Vektorisierung unschlagbar. Sie ist schneller, sauberer und ermöglicht es Ihnen, sich auf das «Was» statt auf das «Wie» Ihrer Analyse zu konzentrieren. Hier kommt die Apply-Funktion ins Spiel.
Der Mittelwert (FUN) wird mit lapply()auf die ausgewählten Spalten angewendet und als Liste zurückgegeben.
sapply() ist vergleichbar mit lapply(), versucht aber die Ausgabe zu vereinfachen. Sind alle Ergebnisse vom gleichen Typ (z.B. numerisch), ist die Rückgabe ein Vektor anstelle einer Liste.
Wie gross ist die Variabilität in den Daten? Zu den typischen Statistiken, welche die Variabilität messen, gehören:
Spannweite (Range): Die Differenz zwischen dem Maximum und Minimum. Dafür gibt es keine eigene Funktion, aber sie lässt sich leicht mit den Funktionen min() und max() berechnen. Ein anderer Ansatz ist die Verwendung der Funktion range() von Base R, welche einen Vektor zurückgibt, der das Minimum und Maximum aller angegebenen Argumente enthält. Wenn Sie diese mit diff() umschliessen, können Sie die Spannweite berechnen.
Interquartilsabstand (IQR): Zur Berechnung wird eine Stichprobe nach Grösse sortiert und das 25%-Quartil vom 75%-Quartil subtrahiert. In R können Sie dazu die Funktion IQR() aus dem stats-Paket verwenden. Im Gegensatz zur Spannweite können so Ausreisser, die das Ergebnis verzerren, umgangen werden.
Varianz: Entspricht dem Mittelwert der quadrierten Differenz zum Mittelwert. Sie können die eingebaute Funktion var() verwenden, um die Varianz zu ermitteln.
Standardabweichung: Entspricht der Quadratwurzel der Varianz. Sie können die integrierte Funktion sd() verwenden, um die Standardabweichung zu finden.
Variationskoeffizient: Dieser ist neben der Varianz und der Standardabweichung ein weiteres Streuungsmass der deskriptiven Statistik. Als relatives Streuungsmass bzw. normierte Standardabweichung hängt der Variationskoeffizient (sd() / mean()) im Gegensatz zu den beiden anderen Kennzahlen nicht von der Masseinheit der statistischen Variable ab. Der Variationskoeffizient ist jedoch nur sinnvoll für Messreihen mit ausschliesslich positiven (oder ausschliesslich negativen) Werten.
Die Position des grössten Wertes kann mit which.max() ermittelt werden. Für das Minimum gibt es das entsprechende Pendant mit which.min().
Code anzeigen
max(penguins$bill_length_mm, na.rm =TRUE)
[1] 59.6
Code anzeigen
which.max(penguins$bill_length_mm)
[1] 186
map
Durch die Verwendung der map()-Funktion des Pakets purrr können Sie viele for-Schleifen durch Code ersetzen, der sowohl kürzer als auch einfacher zu lesen ist.
Code anzeigen
# Spalten auswählen, um das Mass der Varianz zu analysierencols <- penguins |>select(c(bill_length_mm, bill_depth_mm)) |>drop_na()
Wenn Sie über mehrere Listen gleichzeitig iterieren müssen, sind map2() und pmap() hilfreich.
Code anzeigen
# list_2 <-list("Waadt", "Genf", "Wallis")map2(.x = list_1, .y = list_2, .f =~paste0("Bei der Anzahl Lehrverhältnisse nimmt der Kanton ", .y, " den ", .x, ". Platz ein."))
[[1]]
[1] "Bei der Anzahl Lehrverhältnisse nimmt der Kanton Waadt den 1. Platz ein."
[[2]]
[1] "Bei der Anzahl Lehrverhältnisse nimmt der Kanton Genf den 2. Platz ein."
[[3]]
[1] "Bei der Anzahl Lehrverhältnisse nimmt der Kanton Wallis den 3. Platz ein."
quantile
Mit quantile() kann man die Streuung bzw. die Quantile einer Variablen bestimmen.
Code anzeigen
# Streuung von Variablen darstellenquantile(penguins$bill_length_mm, na.rm =TRUE)
Nach der Identifizierung von Dubletten besteht der nächste Schritt oft darin, diese zu entfernen.
Code anzeigen
# Duplikate entfernen mit «duplicated»ergebnis <- (penguins[!duplicated(penguins), ])head(ergebnis)
species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g
1 Adelie Torgersen 39.1 18.7 181 3750
2 Adelie Torgersen 39.5 17.4 186 3800
3 Adelie Torgersen 40.3 18.0 195 3250
4 Adelie Torgersen NA NA NA NA
5 Adelie Torgersen 36.7 19.3 193 3450
6 Adelie Torgersen 39.3 20.6 190 3650
sex year
1 male 2007
2 female 2007
3 female 2007
4 <NA> 2007
5 female 2007
6 male 2007
Code anzeigen
# Duplikate schnell entfernen mit «unique»ergebnis <-unique(x = penguins)head(ergebnis)
species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g
1 Adelie Torgersen 39.1 18.7 181 3750
2 Adelie Torgersen 39.5 17.4 186 3800
3 Adelie Torgersen 40.3 18.0 195 3250
4 Adelie Torgersen NA NA NA NA
5 Adelie Torgersen 36.7 19.3 193 3450
6 Adelie Torgersen 39.3 20.6 190 3650
sex year
1 male 2007
2 female 2007
3 female 2007
4 <NA> 2007
5 female 2007
6 male 2007
Kennwerte zusammenfassen
Die Funktion summary() ermöglicht einen Überblick zu den wichtigsten Kennzahlen eines Datensatzes. Bei numerischen Merkmalen umfassen diese Minimum, 1. Quartil, Median, Mittelwert, 3. Quartil und Maximum.
Code anzeigen
# Zusammenfassung der wichtigsten Kennzahlensummary(penguins)
species island bill_length_mm bill_depth_mm
Adelie :152 Biscoe :168 Min. :32.10 Min. :13.10
Chinstrap: 68 Dream :124 1st Qu.:39.23 1st Qu.:15.60
Gentoo :124 Torgersen: 52 Median :44.45 Median :17.30
Mean :43.92 Mean :17.15
3rd Qu.:48.50 3rd Qu.:18.70
Max. :59.60 Max. :21.50
NAs :2 NAs :2
flipper_length_mm body_mass_g sex year
Min. :172.0 Min. :2700 female:165 Min. :2007
1st Qu.:190.0 1st Qu.:3550 male :168 1st Qu.:2007
Median :197.0 Median :4050 NAs : 11 Median :2008
Mean :200.9 Mean :4202 Mean :2008
3rd Qu.:213.0 3rd Qu.:4750 3rd Qu.:2009
Max. :231.0 Max. :6300 Max. :2009
NAs :2 NAs :2
Die Funktion describe() des Pakets psych liefert ebenfalls eine Zusammenfassung der deskriptiven Statistik. Sie enthält neben den üblichen Lagemassen auch Werte für Schiefe und Kurtosis.
Code anzeigen
describe(penguins$bill_length_mm, na.rm =TRUE)
vars n mean sd median trimmed mad min max range skew kurtosis se
X1 1 342 43.92 5.46 44.45 43.91 7.04 32.1 59.6 27.5 0.05 -0.89 0.3
Mit der Funktion summarise() können beliebige Kennwerte ausgegeben werden. Beispielsweise können Sie das arithmetische Mittel (Mittelwert) und den Median einer numerischen Variablen finden.
Das R-Paket summarytools vereinfacht den Prozess der Datenexploration, indem es Funktionen bereitstellt, die mit minimalem Code umfangreiche Zusammenfassungen Ihrer Daten erzeugen.
Die Funktion dfSummary() liefert eine detaillierte Zusammenfassung, einschliesslich
Verwenden Sie die Funktion descr(), um detaillierte deskriptive Statistiken für Ihre numerischen Variablen zu erhalten. Sie können auswählen, welche Statistiken generiert werden sollen (z.B. «common», «fivenum», usw.).
Code anzeigen
descr(x = penguins, stats ="fivenum")
Non-numerical variable(s) ignored: species, island, sex
Für kategoriale Variablen erzeugt die Funktion freq() Häufigkeitstabellen, welche die Verteilung der Kategorien zeigen. Dies kann Ihnen helfen, die Verteilung und Häufigkeit jeder Kategorie in Ihren Daten zu verstehen.
Die explorative Datenanalyse (EDA) ist entscheidend, um Ihre Daten zu verstehen, Trends zu erkennen und Probleme aufzuspüren, bevor Sie ausführlichere Analysen durchführen. Ohne die richtigen Werkzeuge kann EDA jedoch zeitaufwendig sein. Mit InsightR steht Ihnen eine schnellere und effizientere Methode zur Verfügung, um Ihre Daten zu analysieren und statistische Kennwerte zusammenzufassen.
skimr
Die Kernfunktion von skimr ist skim(), die für die Arbeit mit (gruppierten) Datenrahmen entwickelt wurde. Wie summary() zeigt skim() Statistiken bzw. Ergebnisse für jede Spalte.
Code anzeigen
# Zusammenfassung der wichtigsten Kennzahlen und fehlenden Werteskim(penguins)
Data summary
Name
penguins
Number of rows
344
Number of columns
8
_______________________
Column type frequency:
factor
3
numeric
5
________________________
Group variables
None
Variable type: factor
skim_variable
n_missing
complete_rate
ordered
n_unique
top_counts
species
0
1.00
FALSE
3
Ade: 152, Gen: 124, Chi: 68
island
0
1.00
FALSE
3
Bis: 168, Dre: 124, Tor: 52
sex
11
0.97
FALSE
2
mal: 168, fem: 165
Variable type: numeric
skim_variable
n_missing
complete_rate
mean
sd
p0
p25
p50
p75
p100
hist
bill_length_mm
2
0.99
43.92
5.46
32.1
39.23
44.45
48.5
59.6
▃▇▇▆▁
bill_depth_mm
2
0.99
17.15
1.97
13.1
15.60
17.30
18.7
21.5
▅▅▇▇▂
flipper_length_mm
2
0.99
200.92
14.06
172.0
190.00
197.00
213.0
231.0
▂▇▃▅▂
body_mass_g
2
0.99
4201.75
801.95
2700.0
3550.00
4050.00
4750.0
6300.0
▃▇▆▃▂
year
0
1.00
2008.03
0.82
2007.0
2007.00
2008.00
2009.0
2009.0
▇▁▇▁▇
GWalkR
Ein neuer Ansatz zur explorativen Datenanalyse in R ist das Paket «GWalkR». Es kombiniert das Paket «htmlwidgets» mit der JavaScript-Bibliothek «Graphic Walker» und verwandelt so den Datenrahmen in eine Tableau-ähnliche Drag&Drop-Benutzeroberfläche. Für alle, die bereits mit Datenvisualisierungssoftware wie Microsoft Power BI oder Tableau gearbeitet haben, bietet GWalkR einen intuitiven Einstieg in die Datenanalyse mit R.
Weitere Pakete
Weitere umfassende und teilweise interaktive Einblicke in importierte Datensätze liefern die nachfolgenden Pakete. Diese bieten unter anderem auch eine erste gute Zusammenfassung der fehlenden Werte (n_missing).
esquisse: RStudio-Add-In für interaktive Datenvisualisierung
radiant: Browserbasierte Schnittstelle für Analysen in R, basierend auf dem shiny-Paket
explore: Vereinfacht die explorative Datenanalyse für bivariate Analysen
dataxray: Interaktive Tabellenschnittstelle für Zusammenfassungen von Daten
Häufigkeitstabellen
table
Die Arbeit mit Häufigkeitstabellen ist eine typische Aufgabe in der Datenanalyse. R bietet hierfür mehrere Möglichkeiten. Wenn Sie z.B. wissen möchten, wie viele Pinguine auf den drei Inseln untersucht wurden, können Sie die Funktion table() verwenden. Den prozentualen Anteil erhält man mit prop.table().
Die Ausgabe der Absolutwerte ist auch mit Hilfe der Funktion count() möglich.
Code anzeigen
count(x = penguins, species, island, sort =TRUE)
species island n
1 Gentoo Biscoe 124
2 Chinstrap Dream 68
3 Adelie Dream 56
4 Adelie Torgersen 52
5 Adelie Biscoe 44
xtabs
Die Funktion xtabs() bietet eine flexible und leistungsstarke Möglichkeit, Häufigkeits- und Summentabellen in R zu erstellen. Dank ihrer Formelschnittstelle ist sie besonders praktisch bei der Arbeit mit Datenrahmen. Für komplexere Aggregationen wie Mittelwerte oder Mediane muss sie jedoch mit anderen Funktionen, wie z.B. wie ftable(), kombiniert werden.
Ein grosser Vorteil von xtabs() gegenüber table() ist, dass die Funktion gut mit Datenrahmen zusammenarbeitet. Es ist nicht nötig, einzelne Spalten zu extrahieren.
Code anzeigen
# Häufigkeitstabellextabs(formula =~ species + sex, # Variablen rechts von ~, um Häufigkeiten zu zählendata = penguins, na.action = na.pass) # Standardwert; NA mit Wert 0 in Tabelle aufnehmen
sex
species female male
Adelie 73 73
Chinstrap 34 34
Gentoo 58 61
Code anzeigen
# Tabelle mit mehreren Dimensionenby(data = penguins, INDICES = penguins$island, FUN =function(subset) {xtabs(formula =~ species + sex, data = subset)})
penguins$island: Biscoe
sex
species female male
Adelie 22 22
Chinstrap 0 0
Gentoo 58 61
------------------------------------------------------------
penguins$island: Dream
sex
species female male
Adelie 27 28
Chinstrap 34 34
Gentoo 0 0
------------------------------------------------------------
penguins$island: Torgersen
sex
species female male
Adelie 24 23
Chinstrap 0 0
Gentoo 0 0
Manchmal müssen Sie nicht nur Häufigkeiten zählen, sondern auch Werte summieren. Setzen Sie dazu eine numerische Variable auf die linke Seite der Formel.
Code anzeigen
# Summentabelleprint("Summierte Schnabellänge pro Pinguinart")
[1] "Summierte Schnabellänge pro Pinguinart"
Code anzeigen
xtabs(formula = bill_length_mm ~ species, data = penguins, na.rm =TRUE)
species
Adelie Chinstrap Gentoo
5857.5 3320.7 5843.1
Grafische Darstellung
Grafische Darstellungen ermöglichen eine schnelle und einfache Interpretation von Daten, indem sie Trends und Muster visuell hervorheben. Zudem bieten sie einen klaren Überblick über grosse Datenmengen und erleichtern es, wichtige Informationen auf einen Blick zu erfassen. Sie unterstützen die effektive Kommunikation komplexer Daten, was besonders in Präsentationen und Berichten nützlich ist.
Die Funktion colors() gibt einen Vektor zurück, der alle in R eingebauten Farbnamen in alphabetischer Reihenfolge enthält, wobei das erste Element «white» ist. So lassen sich schnell passende Farben für das Diagramm finden.
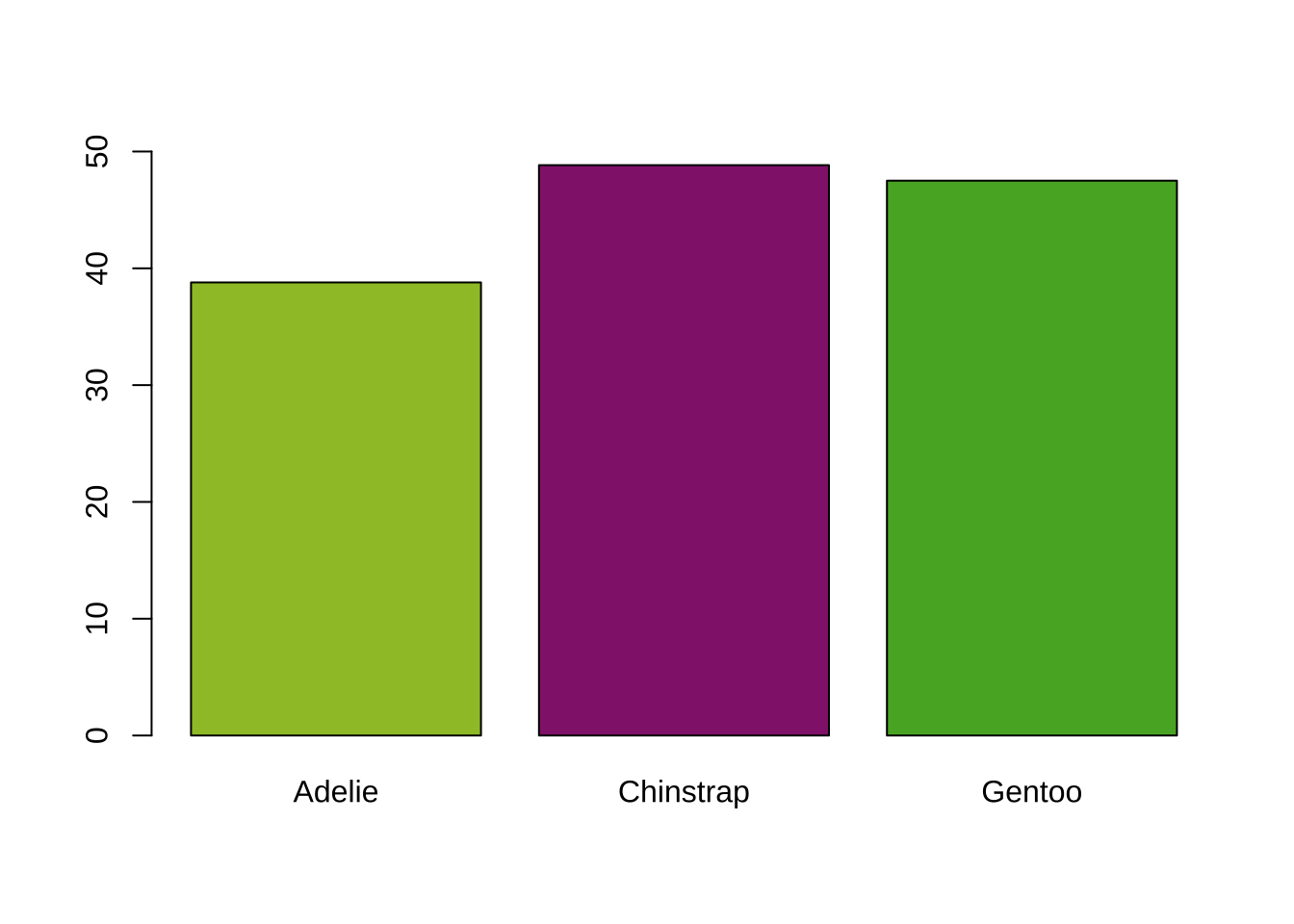
Das Säulendiagramm dient dazu, die Werte unterschiedlicher Kategorien oder Gruppen gegenüberzustellen. Auf der x-Achse sind die Kategorien oder Gruppen dargestellt, während die y-Achse die entsprechenden Werte anzeigt.
Code anzeigen
# Nominalskalierte (kategoriale) oder metrische Variableplot(penguins$species, col ="grey", border =NA, ylim =c(0, 200))
Code anzeigen
# Häufigkeitstabellen mit der Plotfunktion von Base R darstellenbarplot(table(penguins$species), col ="grey", border =NA, main ="Häufigkeitstabelle", ylim =c(0, 200))
# Mittlere Schnabellänge für die drei Pinguinarten berechnenmittlere_schnabellaenge <-tapply(X = penguins$bill_length_mm, INDEX = penguins$species, FUN = mean, na.rm =TRUE)# Säulen mit unterschiedlichen Farbenbarplot(mittlere_schnabellaenge, col =c("#9FC131", "#93257B", "#57AF2C"), ylim =c(0, 50))
Histogramm
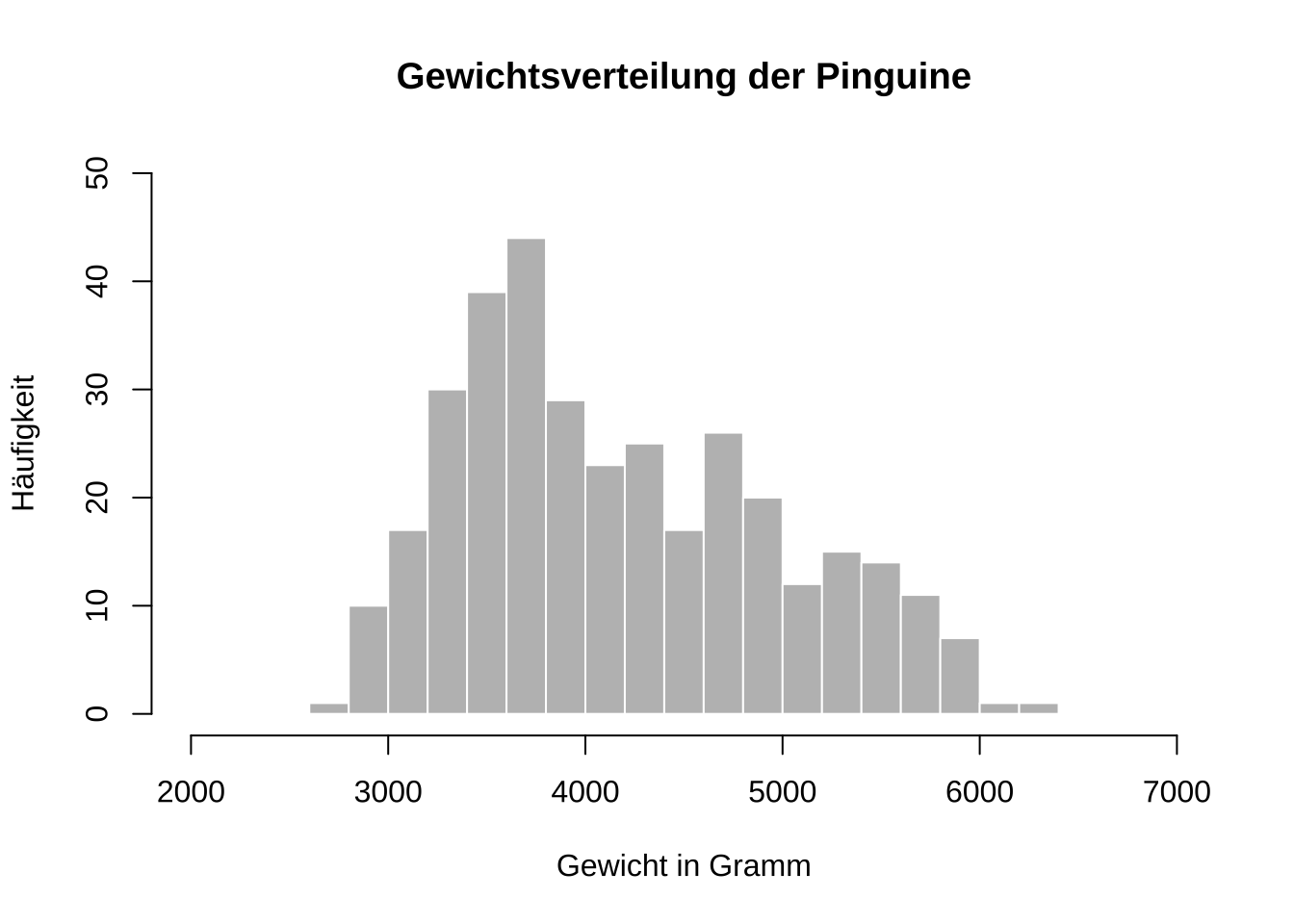
Manchmal sagt ein Bild mehr als tausend Worte. Wenn Datenwissenschaftler eine Variable untersuchen, beispielsweise eine Stichprobe des Gewichts von Pinguinen, interessiert sie die Verteilung dieser Variable. Das heisst, sie wollen wissen, wie die verschiedenen Werte in der Stichprobe verteilt sind. Oft ist die Visualisierung der Daten in Form eines Histogramms der Ausgangspunkt für diese Untersuchung. Dabei werden auf der x-Achse die Werte des Datensatzes und auf der y-Achse die Häufigkeit, also wie oft jeder Wert im Datensatz vorkommt, abgebildet.
Code anzeigen
hist(x = penguins$body_mass_g, breaks =20, col ="grey", border ="white", main ="Gewichtsverteilung der Pinguine", xlim =c(2000, 7000), ylim =c(0, 50), xlab ="Gewicht in Gramm", ylab ="Häufigkeit")
Dichteplot
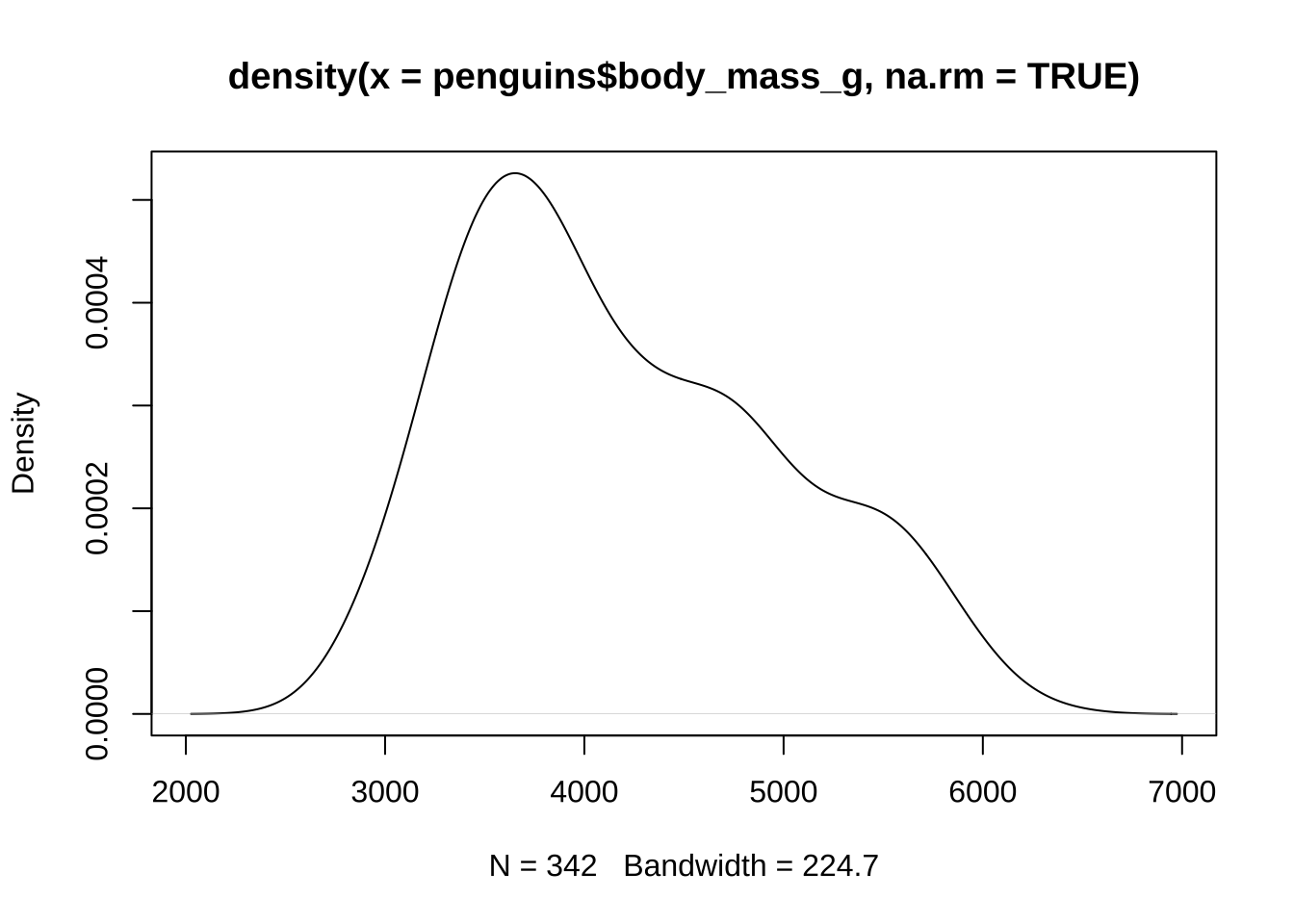
Der Dichteplot ist eine grafische Darstellung der Verteilung einer numerischen Variablen und verwendet die Kerndichteschätzung, um eine glatte Kurve zu erzeugen. Dies ermöglicht eine kontinuierliche und detaillierte Ansicht der Datenverteilung im Vergleich zu einem Histogramm.
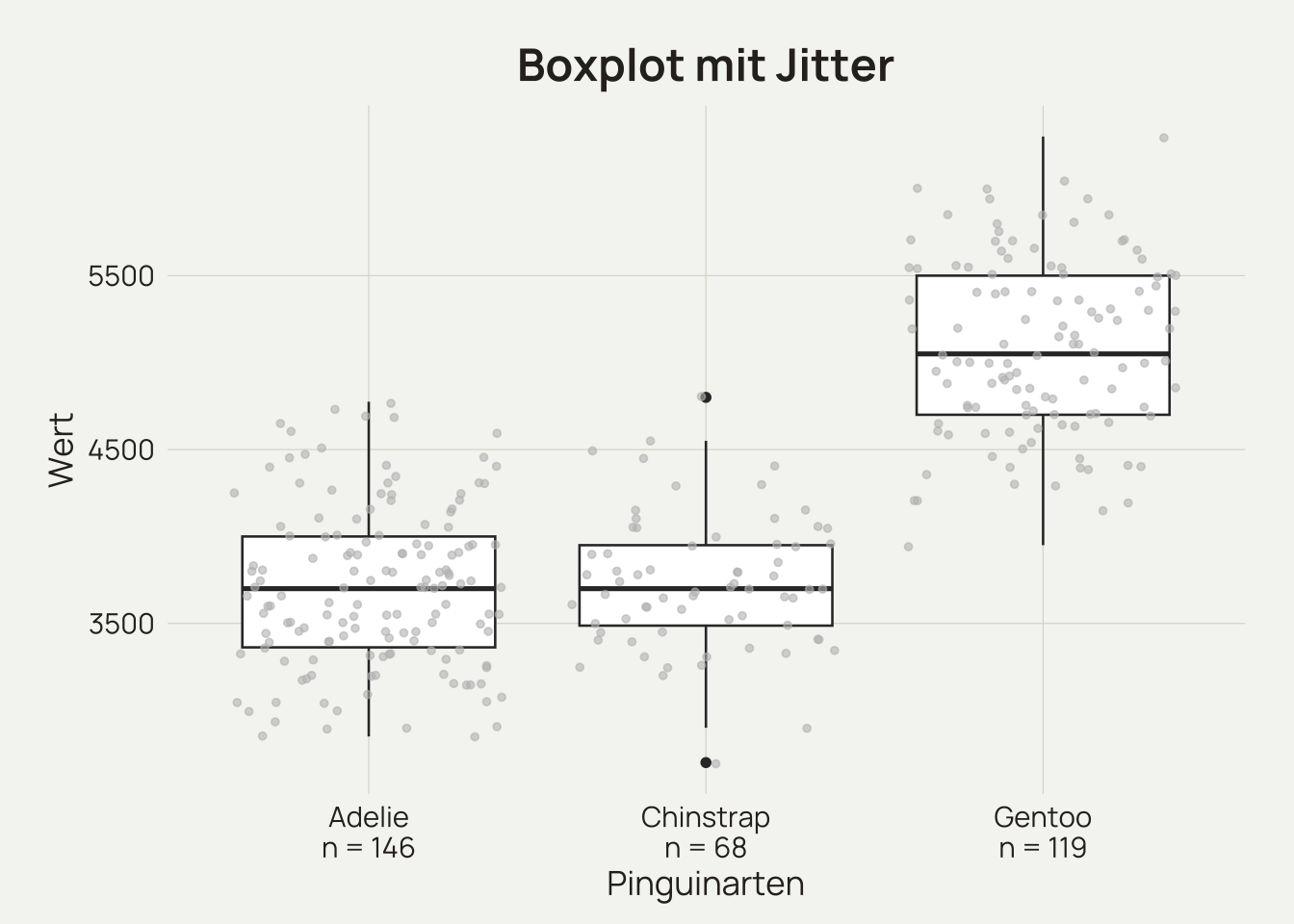
Ein Boxplot, auch Box-and-Whisker-Plot genannt, ist ein Diagramm zur grafischen Darstellung von Datenverteilungen. Er zeigt den Median, die Quartile und mögliche Ausreisser, wodurch man schnell einen Überblick über die Verteilung und Streuung der Daten erhält.
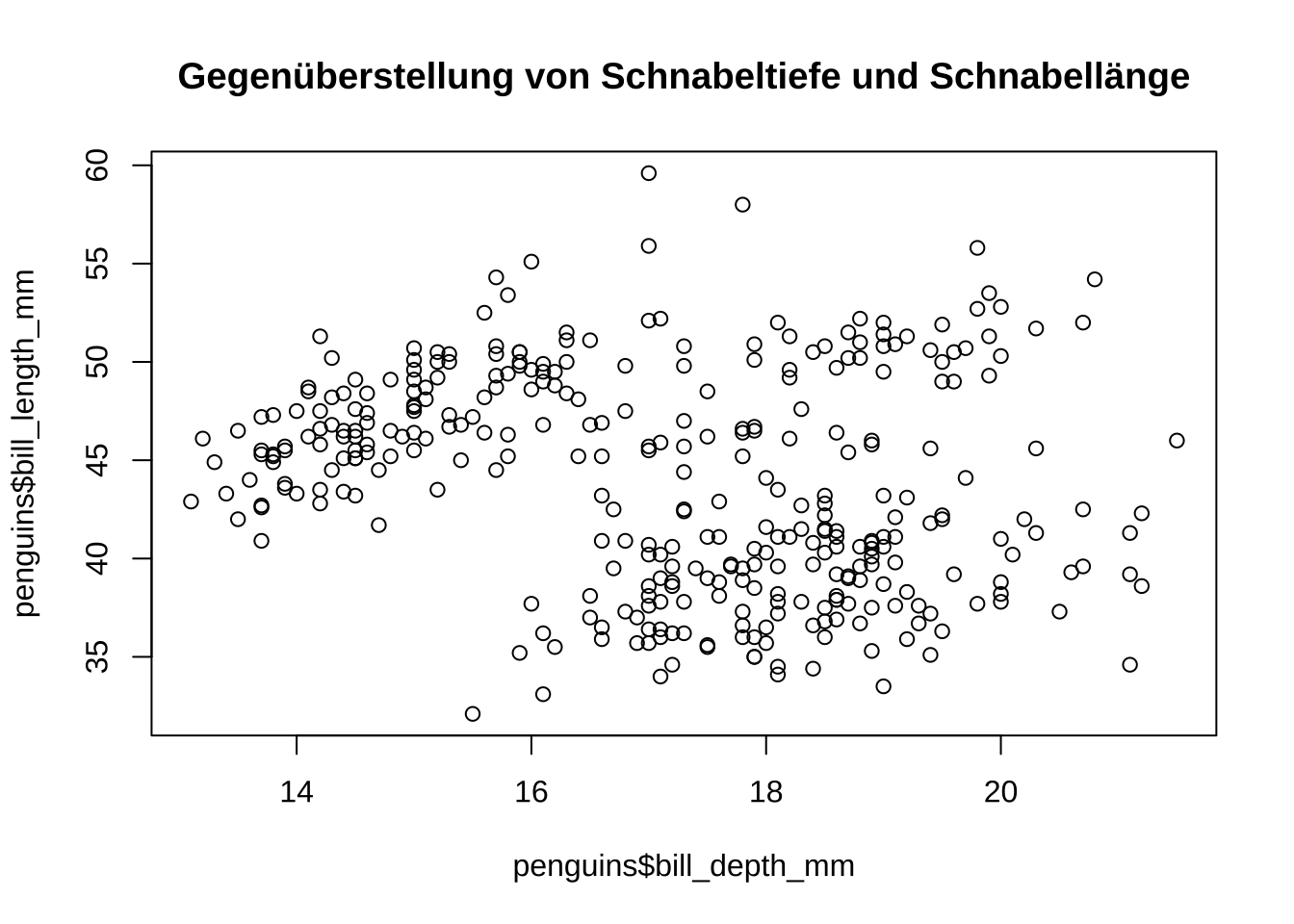
Das Streudiagramm, auch Scatterplot genannt, ist ein Diagramm, das die Beziehung zwischen zwei Variablen darstellt. Jeder Punkt im Diagramm repräsentiert ein Datenpaar, wodurch Muster, Trends oder Korrelationen zwischen den Variablen sichtbar werden.
Code anzeigen
plot(penguins$bill_depth_mm, penguins$bill_length_mm, main ="Gegenüberstellung von Schnabeltiefe und Schnabellänge")
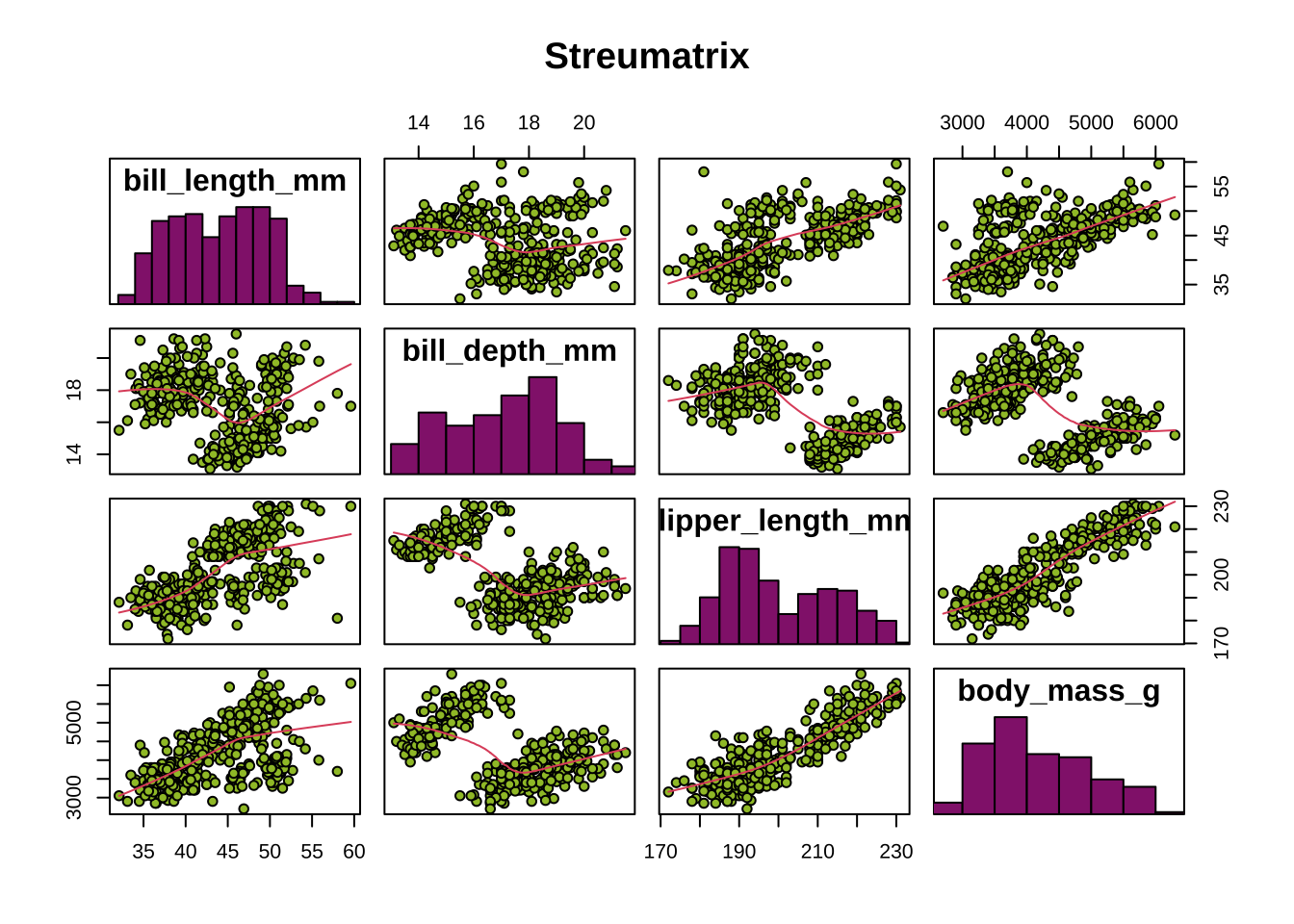
Streumatrix
Die Funktion pairs.panels() erstellt eine Streumatrix, welche die paarweisen Beziehungen zwischen mehreren Variablen in einem Datensatz darstellt. Jede Zelle der Matrix zeigt ein Streudiagramm für ein Variablenpaar, was es ermöglicht, Muster und Korrelationen zwischen allen Variablen gleichzeitig zu erkennen.
Ein Streumatrixdiagramm, bestehend aus Histogrammen und Trendlinien, können Sie auch mit der Funktion pairs() erstellen und so Zusammenhänge sichtbar machen.
Die Funktion ggpairs() aus dem Paket GGally visualisiert ebenfalls paarweise Beziehungen.
Datenaufbereitung
Daten bereinigen
Die Bedeutung der Datenbereinigung wird häufig unterschätzt. Dabei ist sie ein grundlegender Schritt für eine erfolgreiche Datenanalyse. In vielen Fachportalen und Artikeln wird darauf hingewiesen, dass die Datenbereinigung nach dem Pareto-Prinzip ca. 80% der Zeit einer Datenanalyse in Anspruch nimmt und die eigentliche Analyse nur 20%.
Nachdem Sie Ihre Rohdaten importiert und sich einen ersten Überblick verschafft haben, ist es immer eine gute Idee, diese zu bereinigen. Dadurch werden Fehler und andere Probleme reduziert. Dabei werden fehlerhafte Datenpunkte entfernt oder die Daten in ein nützlicheres Format konvertiert. In anderen Situationen können Datenpunkte, die deutlich ausserhalb des erwarteten Bereichs liegen, auch Ausreisser genannt, manchmal aus Analysen entfernt werden. Dies sollte jedoch sorgfältig geprüft werden, um sicherzustellen, dass keine Datenpunkte gelöscht werden, die echte Informationen liefern.
janitor
Bestehende Spaltennamen sind oftmals intuitiv und leicht verständlich, aber nicht unbedingt einfach im Code zu handhaben. Mit der Funktion clean_names() aus dem Paket janitor können Sie Spaltennamen mühelos bereinigen. Sie können wählen, ob Sie alle Namen in Snake Case (alle Wörter klein geschriebenen, getrennt durch Unterstriche), Variationen von Camel Case (Grossbuchstaben zwischen den Wörtern), Title Case oder andere Stile ändern möchten. Weiter werden Leerzeichen in _ umgewandelt und Klammern entfernt. Auf diese Weise sind die Spaltenbezeichnungen leicht verständlich und gut im Code zu verarbeiten.
Datensätze mit leeren oder überflüssigen Zeilen oder Spalten sind keine Seltenheit. Dies gilt insbesondere für Excel-Dateien, die viele leere Zellen enthalten. Diese können mit der Funktion remove_empty() entfernt werden. Ohne Argument werden standardmässig sowohl Zeilen als auch Spalten mit remove_empty() gelöscht. Das kann man anpassen, indem man z.B. which = «rows» oder which = «cols» verwendet.
round_to_fraction() wird verwendet, um auf einen beliebigen Bruch zu runden. Im Beispiel unten wurden die Zahlen auf die nächsten Viertel gerundet (Nenner = 4).
Ein weiteres häufiges Problem bei realen Daten sind Verzerrungen (Bias). «Verzerrung» bezieht sich auf eine menschliche Neigung, bestimmte Arten von Werten häufiger als andere auszuwählen, und zwar auf eine Weise, welche die zugrunde liegende Gesamtheit (Population) der «realen Welt» fehlerhaft darstellt. Verzerrungen lassen sich manchmal identifizieren und verhindern, indem Sie sich bei der Untersuchung von Daten vor Augen halten, woher diese stammen.
Pipe-Operator
R ist eine funktionale Sprache, was bedeutet, dass der Code oft viele Klammern enthält. Bei komplexem Code bedeutet dies, dass diese Klammern ineinander verschachtelt werden müssen. Dadurch ist der R-Code schwer zu lesen und zu verstehen. Hier kommt der Pipe-Operator ins Spiel.
Pipe ist ein Infix-Operator, der im Paket magrittr (Bestandteil von tidyverse) von Stefan Milton Bache eingeführt wurde. Er wird verwendet, um die Ausgabe einer Funktion als Eingabe an eine andere Funktion weiterzuleiten, was den Code im Idealfall leicht lesbar und effizient macht. Mit anderen Worten: Der Pipe-Operator %>% bzw. |> wird verwendet, um eine Folge von mehreren Operationen auf elegante Weise auszudrücken und die Abläufe intuitiver zu gestalten.
Der Pipe-Operator kann wie folgt als Arbeitsanweisung formuliert werden: «Nehmen Sie den Datensatz «penguins» UND DANN filtern Sie nach Gewicht ist gleich 2850g.»
Fehlende Werte finden
Der Umgang mit fehlenden Daten ist eine häufige Herausforderung bei der Datenanalyse und bei Projekten des maschinellen Lernens. In R werden fehlende Werte mit NA (englische Abkürzung für «Not Available») gekennzeichnet. Bei der Arbeit mit Datensätzen ist es wichtig, NA-Werte zu identifizieren und angemessen zu behandeln, um eine verzerrte Analyse oder falsche Ergebnisse zu vermeiden.
Code anzeigen
# Gibt den Wert TRUE (wahr) oder FALSE (falsch) zurückanyNA(penguins)
Die Anzahl der fehlenden Werte für einzelne Spalten wird mit der Funktion sum() berechnet.
Code anzeigen
sum(is.na(penguins$bill_length_mm) ==TRUE)
[1] 2
Eine andere, intuitivere Methode ist, die Summe der fehlenden Werte für jede Spalte zu ermitteln. is.na(df) erzeugt eine logische Matrix, welche die NA-Positionen im Datenrahmen angibt. Die Funktion colSums() summiert dann die TRUE-Werte (die NA repräsentieren) in jeder Spalte und gibt die Anzahl der fehlenden Werte pro Spalte zurück.
Code anzeigen
# Summe der NA-Werte pro SpaltecolSums(is.na(penguins))
species island bill_length_mm bill_depth_mm
0 0 2 2
flipper_length_mm body_mass_g sex year
2 2 11 0
summarise_all() wendet die Funktion sum(is.na(.)) auf jede Spalte an (der Punkt steht hier für jede Spalte) und gibt die Anzahl der NA-Werte für jede Spalte zurück.
Code anzeigen
penguins |>summarise_all(~sum(is.na(.)))
species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g sex
1 0 0 2 2 2 2 11
year
1 0
Die Funktion which() hilft herauszufinden, welche Zeilen fehlende Werte enthalten.
Code anzeigen
# Zeilen mit fehlenden Werten ermittelnwhich(x =is.na(penguins$bill_length_mm) ==TRUE)
[1] 4 272
Sie können die Summe der fehlenden Werte auch für alle Zeilen berechnen. Dies kann bei kleinen Datensätzen nützlich sein.
Code anzeigen
penguins %>%filter(rowSums(is.na(.)) >0)
species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g
1 Adelie Torgersen NA NA NA NA
2 Adelie Torgersen 34.1 18.1 193 3475
3 Adelie Torgersen 42.0 20.2 190 4250
4 Adelie Torgersen 37.8 17.1 186 3300
5 Adelie Torgersen 37.8 17.3 180 3700
6 Adelie Dream 37.5 18.9 179 2975
7 Gentoo Biscoe 44.5 14.3 216 4100
8 Gentoo Biscoe 46.2 14.4 214 4650
9 Gentoo Biscoe 47.3 13.8 216 4725
10 Gentoo Biscoe 44.5 15.7 217 4875
11 Gentoo Biscoe NA NA NA NA
sex year
1 <NA> 2007
2 <NA> 2007
3 <NA> 2007
4 <NA> 2007
5 <NA> 2007
6 <NA> 2007
7 <NA> 2007
8 <NA> 2008
9 <NA> 2009
10 <NA> 2009
11 <NA> 2009
Eine weitere Variante besteht darin, die fehlenden Zeilen mit der Funktion everything() zu filtern.
Code anzeigen
penguins |>filter(if_any(everything(), is.na))
species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g
1 Adelie Torgersen NA NA NA NA
2 Adelie Torgersen 34.1 18.1 193 3475
3 Adelie Torgersen 42.0 20.2 190 4250
4 Adelie Torgersen 37.8 17.1 186 3300
5 Adelie Torgersen 37.8 17.3 180 3700
6 Adelie Dream 37.5 18.9 179 2975
7 Gentoo Biscoe 44.5 14.3 216 4100
8 Gentoo Biscoe 46.2 14.4 214 4650
9 Gentoo Biscoe 47.3 13.8 216 4725
10 Gentoo Biscoe 44.5 15.7 217 4875
11 Gentoo Biscoe NA NA NA NA
sex year
1 <NA> 2007
2 <NA> 2007
3 <NA> 2007
4 <NA> 2007
5 <NA> 2007
6 <NA> 2007
7 <NA> 2007
8 <NA> 2008
9 <NA> 2009
10 <NA> 2009
11 <NA> 2009
Ein anderer Ansatz zur Auswahl von Zeilen mit NA-Werten bzw. ohne NA ist die Verwendung der Funktion complete.cases().
species island bill_length_mm bill_depth_mm flipper_length_mm
4 Adelie Torgersen NA NA NA
9 Adelie Torgersen 34.1 18.1 193
10 Adelie Torgersen 42.0 20.2 190
11 Adelie Torgersen 37.8 17.1 186
12 Adelie Torgersen 37.8 17.3 180
48 Adelie Dream 37.5 18.9 179
179 Gentoo Biscoe 44.5 14.3 216
219 Gentoo Biscoe 46.2 14.4 214
257 Gentoo Biscoe 47.3 13.8 216
269 Gentoo Biscoe 44.5 15.7 217
272 Gentoo Biscoe NA NA NA
body_mass_g sex year
4 NA <NA> 2007
9 3475 <NA> 2007
10 4250 <NA> 2007
11 3300 <NA> 2007
12 3700 <NA> 2007
48 2975 <NA> 2007
179 4100 <NA> 2007
219 4650 <NA> 2008
257 4725 <NA> 2009
269 4875 <NA> 2009
272 NA <NA> 2009
vis_miss
Die Funktion vis_miss() aus dem naniar-Paket visualisiert das Muster der fehlenden Daten in Ihrem Datensatz und erleichtert so die Entscheidung, wie mit fehlenden Daten umzugehen ist.
Fehlende Werte ersetzen
In R stehen für das Ersetzen von Werten und Löschen von Zeilen verschiedene Funktionen aus den Paketen tidyr und dplyr zur Verfügung. Beide Pakete sind in tidyverse enthalten.
Der Entscheid, ob fehlende Werte ersetzt oder die betroffenen Zeilen gelöscht werden, ist in erster Linie vom vorliegenden Datensatz abhängig. Bei umfangreichen Datensätzen ist ein Löschen von Zeilen weniger problematisch als bei solchen mit nur wenigen Beobachtungen.
Fehlende numerische Werte können durch die Lageparameter arithmetisches Mittel und Median der Variable oder durch die Zahl 0 ersetzt werden. Es ist für jede Spalte einzeln zu prüfen, welches Vorgehen sinnvoll ist.
species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g
1 Adelie Torgersen 39.1 18.7 181 3750
2 Adelie Torgersen 39.5 17.4 186 3800
3 Adelie Torgersen 40.3 18.0 195 3250
4 Adelie Torgersen NA NA NA 0
5 Adelie Torgersen 36.7 19.3 193 3450
6 Adelie Torgersen 39.3 20.6 190 3650
sex year
1 male 2007
2 female 2007
3 female 2007
4 <NA> 2007
5 female 2007
6 male 2007
Fehlende Werte mit bestimmtem Wert ersetzen
Die Funktion replace_na() ist ein praktisches Tool in der R-Werkzeugkiste, um bestimmte Elemente in Vektoren und Datensets zu ändern. Sie ermöglicht es, unerwünschte Werte durch neue zu ersetzen.
Code anzeigen
mean_weight <-mean(penguins$body_mass_g, na.rm =TRUE) # Mittelwert ohne NA berechnen# NA in einer Spalte ersetzenpenguins_val <- penguins |>mutate(body_mass_g =replace_na(data = body_mass_g, replace = mean_weight))# NA in mehreren Spalten ersetzenpenguins_val <- penguins_val |>replace_na(list(bill_length_mm =0, bill_depth_mm =0))head(penguins_val)
species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g
1 Adelie Torgersen 39.1 18.7 181 3750.000
2 Adelie Torgersen 39.5 17.4 186 3800.000
3 Adelie Torgersen 40.3 18.0 195 3250.000
4 Adelie Torgersen 0.0 0.0 NA 4201.754
5 Adelie Torgersen 36.7 19.3 193 3450.000
6 Adelie Torgersen 39.3 20.6 190 3650.000
sex year
1 male 2007
2 female 2007
3 female 2007
4 <NA> 2007
5 female 2007
6 male 2007
Zeilen mit fehlenden Werten entfernen
Zeilen mit fehlenden Werten können Sie mit der Funktion drop_na() aus dem Paket tidyr löschen.
Um die Zeilen eines Datensatzes zu sortieren, können Sie die Funktion arrange() aus dem Paket dplyr verwenden, welche die Zeilen eines Datenrahmens nach den Spaltenwerten sortiert.
Code anzeigen
# Nach Gewicht aufsteigend sortierenpenguins |>select(species, island, body_mass_g, sex) |>arrange(body_mass_g) |>head(n =10)
# Nach Gewicht absteigend sortierenpenguins |>select(species, island, body_mass_g, sex) |>arrange(desc(body_mass_g)) |>head(n =10)
species island body_mass_g sex
1 Gentoo Biscoe 6300 male
2 Gentoo Biscoe 6050 male
3 Gentoo Biscoe 6000 male
4 Gentoo Biscoe 6000 male
5 Gentoo Biscoe 5950 male
6 Gentoo Biscoe 5950 male
7 Gentoo Biscoe 5850 male
8 Gentoo Biscoe 5850 male
9 Gentoo Biscoe 5850 male
10 Gentoo Biscoe 5800 male
Eine alternative Variante ist das Verwenden der Funktion order() von Base R.
Datensätze enthalten oft mehr Informationen, als für eine bestimmte Analyse benötigt werden. Durch das Weglassen irrelevanter Spalten können Sie Ihre Daten straffen und sich auf das Wesentliche konzentrieren. Dies macht nicht nur den Code sauberer, sondern verbessert auch die Leistung bei der Arbeit mit grossen Datensätzen.
Select verfügt über eine Reihe von Hilfsfunktionen, mit denen Sie Variablen anhand ihrer Eigenschaften auswählen können. Zum Beispiel kann es sein, dass Sie nur an numerischen Merkmalen interessiert sind.
Die Select-Funktion in Kombination mit contains() erleichtert die Auswahl von Spalten, welche eine bestimmte Zeichenfolge enthalten. Weitere Auswahlhilfen sind z.B. starts_with() oder ends_with().
species bill_length_mm bill_depth_mm flipper_length_mm body_mass_g sex
1 Adelie 39.1 18.7 181 3750 male
2 Adelie 39.5 17.4 186 3800 female
3 Adelie 40.3 18.0 195 3250 female
4 Adelie NA NA NA NA <NA>
5 Adelie 36.7 19.3 193 3450 female
6 Adelie 39.3 20.6 190 3650 male
7 Adelie 38.9 17.8 181 3625 female
8 Adelie 39.2 19.6 195 4675 male
9 Adelie 34.1 18.1 193 3475 <NA>
10 Adelie 42.0 20.2 190 4250 <NA>
In R stehen weitere Optionen zur Verfügung, um bestimmte Spalten in einem Datensatz zu adressieren. Eine Variante ist der «Accessor» (Dollar-Notation) und eine andere ist das Verwenden der Pull-Funktion aus dem Paket dplyr.
Code anzeigen
# Accessorhead(penguins$bill_length_mm, n =5)
[1] 39.1 39.5 40.3 NA 36.7
Code anzeigen
# Pull-Funktionhead(pull(.data = penguins, all_of(bill_length_mm)), n =5)
[1] 39.1 39.5 40.3 NA 36.7
Spalten hinzufügen
Das Erstellen und Modifizieren von Spalten übernimmt die Funktion mutate() aus dem Paket dplyr. Die Struktur für das Hinzufügen oder Ändern von Spalten ähnelt derjenigen beim Filtern.
species island ID bill_length_mm bill_depth_mm flipper_length_mm
1 Adelie Torgersen 1 39.1 18.7 181
2 Adelie Torgersen 2 39.5 17.4 186
3 Adelie Torgersen 3 40.3 18.0 195
4 Adelie Torgersen 4 NA NA NA
5 Adelie Torgersen 5 36.7 19.3 193
6 Adelie Torgersen 6 39.3 20.6 190
body_mass_g sex year
1 3750 male 2007
2 3800 female 2007
3 3250 female 2007
4 NA <NA> 2007
5 3450 female 2007
6 3650 male 2007
Präfix zu Spaltennamen hinzufügen
Das Hinzufügen eines Präfixes zum Spaltennamen kann nützlich sein, um Variablen zu organisieren, die Lesbarkeit zu verbessern oder Namenskonflikte beim Zusammenführen von Datensätzen zu vermeiden.
Code anzeigen
# Präfix mit paste() und colnames() hinzufügencolnames(penguins_mean) <-paste("pingu_", colnames(penguins_mean), sep ="")head(penguins_mean)
Das Kombinieren von Spalten in R ist eine gängige Operation bei der Arbeit mit Datensätzen. Die Funktion unite() ist dabei eine komfortable Möglichkeit, mehrere Spalten zu einer Spalte zusammenzufassen.
Code anzeigen
# Mehrere Spalten vereinen und Originalspalten löschenpenguins |>unite(col ="penguins_gesamt", species, island, year, sep =", ", remove =TRUE) |>head()
penguins_gesamt bill_length_mm bill_depth_mm flipper_length_mm
1 Adelie, Torgersen, 2007 39.1 18.7 181
2 Adelie, Torgersen, 2007 39.5 17.4 186
3 Adelie, Torgersen, 2007 40.3 18.0 195
4 Adelie, Torgersen, 2007 NA NA NA
5 Adelie, Torgersen, 2007 36.7 19.3 193
6 Adelie, Torgersen, 2007 39.3 20.6 190
body_mass_g sex
1 3750 male
2 3800 female
3 3250 female
4 NA <NA>
5 3450 female
6 3650 male
Code anzeigen
# Spalten zusammenführen mit paste()paste(penguins$species, "Pinguine leben auf", penguins$island, "und sind", # Zahlen-, Faktor- oder Datumsspalten: Vor Kombi. mit as.character() in Zeichen umwandelnas.character(penguins$body_mass_g), "Gramm schwer.") |>first()
[1] "Adelie Pinguine leben auf Torgersen und sind 3750 Gramm schwer."
Datensätze zusammenführen
Das Zusammenführen mehrerer Datensätze ist eine wichtige Fähigkeit bei der Datenaufbereitung. Unabhängig davon, ob Sie mit kleinen oder grossen Datensätzen arbeiten, kann das Zusammenführen die Effizienz erheblich steigern.
# Daten zeilenweise zusammenführen, sinnvoll bei gleichen Spalten# rbind(sample1, sample2)
list2DF
Die Funktion list2DF() erstellt einen Datenrahmen aus einer Liste.
list2DF(x = random_list)
ldply
ldply() kann aus den Elementen einer Liste einen Datenrahmen erzeugen.
ldply(.data = random_list, .fun = data.frame)
Datensätze zusammenführen
Das Zusammenführen von Datensätzen, die auf mehreren Spalten basieren, ist ein gängiger Vorgang in der Datenanalyse. Durch das Verwenden von Funktionen wie merge() oder den Join-Funktionen des Pakets dplyr können Sie Daten aus verschiedenen Quellen effizient kombinieren und gleichzeitig flexibel mit nicht übereinstimmenden Werten umgehen.
Mit den Funktionen merge() und *_join() lässt sich auch die SVERWEIS-Funktionalität von Excel replizieren.
Code anzeigen
# Zur Veranschaulichung werden einige Regionen und Schulkantone durch «unbekannt» ersetzt.bgb_staat_clean_ab <- bgb_staat_clean |>select(geschlecht_mann, geschlecht_frau, schulkanton, region) |>mutate(schulkanton =ifelse(schulkanton %in%c("Aargau", "Appenzell A. Rh.", "Appenzell I. Rh.", "Basel-Landschaft", "Basel-Stadt", "Bern"), yes ="unbekannt", no = schulkanton)) |>mutate(region =ifelse(schulkanton =="unbekannt", yes ="unbekannt", no = region)) |># Probleme mit der Gross-/Kleinschreibung des Schlüssels beheben:mutate(schulkanton =tolower(schulkanton), region =tolower(region))
Überprüfen Sie die Datentypen und die Eindeutigkeit der Schlüssel, bevor Sie mit dem Zusammenführen der Datensätze beginnen.
Code anzeigen
# Datentypen vor dem Zusammenführen prüfenclass(bgb_staat_clean_ab$region)
[1] "character"
Code anzeigen
class(bgb_typ_clean_efz_eba$region)
[1] "character"
Code anzeigen
# Prüfen, ob Schlüssel doppelt vorhanden sind# Die Kombination Region = «unbekannt» und Schulkanton = «unbekannt» kommt hier mehrfach vorbgb_staat_clean_ab |>group_by(region, schulkanton) |>filter(n() >1)
# Auf fehlende Übereinstimmungen prüfenmissing_matches <-setdiff(bgb_staat_clean_ab$region, bgb_typ_clean_efz_eba$region)if (length(missing_matches) >0) {warning("Nicht übereinstimmende Werte gefunden: ", paste(missing_matches, collapse =", "))} else {"Es wurden keine Fehler gefunden."}
Warning: Nicht übereinstimmende Werte gefunden: unbekannt
Inner Join kombiniert Zeilen aus beiden Datensätzen, die auf der Grundlage der angegebenen Spalten übereinstimmen. Zeilen mit nicht übereinstimmenden Werten werden ausgeschlossen.
Code anzeigen
# Datensatz auf Basis von «Region» und «Schulkanton» mit Inner Join von dplyr zusammenführenbgb_staat_clean_ab |>inner_join(y = bgb_typ_clean_efz_eba, by =c("region", "schulkanton"))
# Datensatz auf Basis von «Region» und «Schulkanton» mit merge() zusammenführenmerge(x = bgb_staat_clean_ab, y = bgb_typ_clean_efz_eba, by =c("region", "schulkanton"))
Left Join behält alle Zeilen des linken Datensatzes (bgb_staat_clean_ab) bei und fügt die entsprechenden Zeilen des rechten Datensatzes (bgb_typ_clean_efz_eba) ein. Wenn es keine Übereinstimmung gibt, werden NA-Werte für die Spalten von «bgb_typ_clean_efz_eba» eingefügt.
Die Funktion left_join() aus dem dplyr-Paket kann auch verwendet werden, um Werte zu ersetzen.
Code anzeigen
# Datensatz auf Basis von «Region» und «Schulkanton» mit Left Join von dplyr zusammenführenbgb_staat_clean_ab |>left_join(y = bgb_typ_clean_efz_eba, by =c("region", "schulkanton"))
# Datensatz auf Basis von «Region» und «Schulkanton» mit merge() zusammenführenmerge(x = bgb_staat_clean_ab, y = bgb_typ_clean_efz_eba, by =c("region", "schulkanton"), all.x =TRUE)
Right Join behält alle Zeilen des rechten Datensatzes (bgb_typ_clean_efz_eba) bei und fügt die entsprechenden Zeilen des linken Datensatzes (bgb_staat_clean_ab) ein. Wenn es keine Übereinstimmung gibt, werden NA-Werte für die Spalten von «bgb_staat_clean_ab» eingefügt.
Code anzeigen
# Datensatz auf Basis von «Region» und «Schulkanton» mit Right Join von dplyr zusammenführenbgb_staat_clean_ab |>right_join(y = bgb_typ_clean_efz_eba, by =c("region", "schulkanton"))
# Datensatz auf Basis von «Region» und «Schulkanton» mit merge() zusammenführenmerge(x = bgb_staat_clean_ab, y = bgb_typ_clean_efz_eba, by =c("region", "schulkanton"), all.y =TRUE)
Bei einem Full Join werden alle Zeilen aus beiden Datensätzen beibehalten, wobei für Spalten, für die keine Übereinstimmung besteht, NA-Werte verwendet werden.
Code anzeigen
# Datensatz auf Basis von «Region» und «Schulkanton» mit Full Join von dplyr zusammenführenbgb_staat_clean_ab |>full_join(y = bgb_typ_clean_efz_eba, by =c("region", "schulkanton"))
geschlecht_mann geschlecht_frau schulkanton region typ_efz
1 11298 7529 waadt genferseeregion 17888
2 5149 3022 wallis genferseeregion 7696
3 5823 3381 genf genferseeregion 8625
4 4450 2482 freiburg espace mittelland 6652
5 3246 2462 solothurn espace mittelland 5224
6 2992 1909 neuenburg espace mittelland 4628
7 2958 2794 unbekannt unbekannt NA
8 3880 2066 unbekannt unbekannt NA
9 9504 6588 unbekannt unbekannt NA
10 23106 18935 zürich zürich 38899
11 665 372 glarus ostschweiz 970
12 1135 913 schaffhausen ostschweiz 1940
13 574 349 unbekannt unbekannt NA
14 NA NA unbekannt unbekannt NA
15 9785 6666 st. gallen ostschweiz 15395
16 2977 1931 graubünden ostschweiz 4596
17 3588 2212 thurgau ostschweiz 5499
18 8433 5765 luzern zentralschweiz 13271
19 366 213 uri zentralschweiz 569
20 1882 833 schwyz zentralschweiz 2621
21 520 234 obwalden zentralschweiz 632
22 384 223 nidwalden zentralschweiz 591
23 1829 1304 zug zentralschweiz 2961
24 5653 3548 tessin tessin 8519
25 NA NA basel-stadt nordwestschweiz 5424
26 NA NA basel-landschaft nordwestschweiz 5364
27 NA NA aargau nordwestschweiz 14838
28 NA NA appenzell a. rh. ostschweiz 875
29 NA NA appenzell i. rh. ostschweiz NA
typ_eba
1 913
2 462
3 474
4 280
5 484
6 263
7 NA
8 NA
9 NA
10 2450
11 67
12 108
13 NA
14 NA
15 1056
16 188
17 301
18 927
19 10
20 94
21 122
22 16
23 172
24 682
25 328
26 582
27 1254
28 48
29 NA
Code anzeigen
# Datensatz auf Basis von «Region» und «Schulkanton» mit merge() zusammenführenmerge(x = bgb_staat_clean_ab, y = bgb_typ_clean_efz_eba, by =c("region", "schulkanton"), all =TRUE)
region schulkanton geschlecht_mann geschlecht_frau typ_efz
1 espace mittelland freiburg 4450 2482 6652
2 espace mittelland neuenburg 2992 1909 4628
3 espace mittelland solothurn 3246 2462 5224
4 genferseeregion genf 5823 3381 8625
5 genferseeregion waadt 11298 7529 17888
6 genferseeregion wallis 5149 3022 7696
7 nordwestschweiz aargau NA NA 14838
8 nordwestschweiz basel-landschaft NA NA 5364
9 nordwestschweiz basel-stadt NA NA 5424
10 ostschweiz appenzell a. rh. NA NA 875
11 ostschweiz appenzell i. rh. NA NA NA
12 ostschweiz glarus 665 372 970
13 ostschweiz graubünden 2977 1931 4596
14 ostschweiz schaffhausen 1135 913 1940
15 ostschweiz st. gallen 9785 6666 15395
16 ostschweiz thurgau 3588 2212 5499
17 tessin tessin 5653 3548 8519
18 unbekannt unbekannt 9504 6588 NA
19 unbekannt unbekannt NA NA NA
20 unbekannt unbekannt 2958 2794 NA
21 unbekannt unbekannt 3880 2066 NA
22 unbekannt unbekannt 574 349 NA
23 zentralschweiz luzern 8433 5765 13271
24 zentralschweiz nidwalden 384 223 591
25 zentralschweiz obwalden 520 234 632
26 zentralschweiz schwyz 1882 833 2621
27 zentralschweiz uri 366 213 569
28 zentralschweiz zug 1829 1304 2961
29 zürich zürich 23106 18935 38899
typ_eba
1 280
2 263
3 484
4 474
5 913
6 462
7 1254
8 582
9 328
10 48
11 NA
12 67
13 188
14 108
15 1056
16 301
17 682
18 NA
19 NA
20 NA
21 NA
22 NA
23 927
24 16
25 122
26 94
27 10
28 172
29 2450
Kategoriale Variablen
Faktoren sind wichtige Datenstrukturen in R, die häufig zur Darstellung kategorialer Variablen verwendet werden. Sie speichern sowohl die Werte der kategorialen Variablen als auch die entsprechenden Stufen. Jede Faktorstufe repräsentiert eine eindeutige Kategorie innerhalb der Variablen.
Numerische in kategoriale Werte konvertieren
Bei manchen Variablen ist es sinnvoll, sie von einem numerischen Wert in eine kategoriale Grösse zu konvertieren. Aber auch nichtnumerische Variablen können in einen Faktor transformiert werden.
Mit der Funktion cut() können kontinuierliche Variablen in Intervalle oder sogenannte «Bins» unterteilt werden, die auf bestimmten Messpunkten basieren. Auf diese Weise können Sie numerische Daten in kategorische Daten umwandeln, die sich leichter analysieren und interpretieren lassen.
Die Umbenennung von Faktorstufen kann die Lesbarkeit und Interpretierbarkeit Ihrer kategorialen Daten erheblich verbessern. Das Paket forcats bietet dafür leistungsstarke Werkzeuge.
Bei der Arbeit mit Textdaten besteht eine häufige Aufgabe darin, zu prüfen, ob ein Zeichen oder eine Teilzeichenkette in einer längeren Zeichenkette enthalten ist. R stellt für diesen Zweck leistungsfähige Instrumente zur Verfügung, z.B. die Funktion grepl() von Base R, str_detect() von stringr oder stri_detect_fixed() von stringi.
Die Funktion str_length() gibt die Anzahl der Zeichen (einschliesslich Leer- und Satzzeichen) zurück. Sonderzeichen, die mit dem Escape-Zeichen «\» beginnen, zählen dabei als ein Zeichen.
Code anzeigen
str_length(string = text)
[1] 42
Bei manuell eingegebenen Daten können versehentlich zusätzliche Leerzeichen eingefügt worden sein. Die Funktion str_squish() entfernt unsichtbare Leerzeichen am Anfang und am Ende einer Zeichenkette und fasst mehrere Leerzeichen in der Mitte zu einem zusammen.
Die Funktion grep() ist ein leistungsfähiges Werkzeug von Base R für Mustervergleiche und das Suchen in Zeichenketten. Standardmässig führt grep() einen Teilabgleich durch, was zu unerwarteten Ergebnissen führen kann, wenn Sie nach exakten Übereinstimmungen suchen. Eine effektive Methode für den exakten Abgleich ist die Verwendung der Anker ^ (Anfang der Zeichenfolge) und $ (Ende der Zeichenfolge). Dadurch wird sichergestellt, dass der gesuchte Begriff die gesamte Zeichenkette ist und nicht nur ein Teil davon.
grep(pattern ="^Zeugnis$", x = text) # Weitere Argumente: ignore.case = TRUE, value = TRUE
[1] 2
Code anzeigen
# Reguläre Ausdrücke für komplexe Suchmustergrep(pattern ="^[ZE]", x = text)
[1] 2 3 4
Code anzeigen
# Positionen zurückgeben, bei denen eine Übereinstimmung vorliegtgrep(pattern ="Zeugnis|EFZ", # Suchmuster mit OR kombinierenx = text)
[1] 2 3 4
Um einen Vergleich zu ermöglichen, wird derselbe Vorgang mit dem Paket stringr durchgeführt.
Code anzeigen
# Zeichenketten zurückgeben, bei denen eine Übereinstimmung vorliegtstr_subset(string = text, pattern ="Zeugnis|EFZ", negate =FALSE) # «negate = TRUE» gibt diejenigen ohne Übereinstimmung zurück
[1] "Zeugnis" "Zeugnisse" "EFZ"
Bei der Arbeit mit grossen Datensätzen kann die Leistung der verschiedenen Abgleichsmethoden erheblich sein. Im Allgemeinen ist die Verwendung von == oder %in% für exakte Vergleiche in einfachen Fällen schneller. grep() ist jedoch effizienter, wenn Sie mit komplexen Mustern arbeiten oder wenn Sie die zusätzlichen Funktionen wie ignore.case oder die value-Optionen verwenden wollen.
Code anzeigen
any(text =="Zeugnis")
[1] TRUE
Code anzeigen
text[text =="Zeugnis"]
[1] "Zeugnis"
Ungefähre Übereinstimmung finden
Die Funktion agrep() von Base R wird für die annähernde Übereinstimmung von Zeichenketten verwendet, auch bekannt als Fuzzy Matching.
Die Funktion ist besonders nützlich für
Suche nach ähnlichen Zeichenfolgen in einem Datensatz
Durchführung unscharfer Suchen in Textfeldern
Korrektur von Rechtschreibfehlern in Textdaten
agrep() ist ein leistungsfähiges Werkzeug für das Fuzzy Matching, aber es ist wichtig, geeignete Parameter zu wählen (insbesondere max.distance), um die richtige Balance zwischen dem Erkennen relevanter Übereinstimmungen und dem Vermeiden falsch positiver Ergebnisse zu finden. Bei sehr umfangreichen Abgleichsaufgaben kann die Verwendung der Funktion langsam sein.
Code anzeigen
agrep(pattern ="zügnisse", x = text, max.distance =0.4) # Maximal zulässige Distanz für einen Treffer
[1] 1 2 3
Zeichenketten verbinden
Beim Zusammenfügen von Zeichenketten werden zwei oder mehrere Elemente miteinander verbunden. Dabei spielt es keine Rolle, ob Sie mit Textdaten arbeiten oder dynamische Ausgaben erzeugen.
Code anzeigen
text <-str_c(bgb_typ_clean$typ_efz[1], " Lernende wurden im Kanton ", bgb_typ_clean$schulkanton[1], " mit einem eidg. Fähigkeitszeugnis (EFZ) ausgezeichnet.", sep ="") # Ohne Separator ist str_c() äquivalent zu paste0()writeLines(text = text)
17888 Lernende wurden im Kanton Waadt mit einem eidg. Fähigkeitszeugnis (EFZ) ausgezeichnet.
Mithilfe der Funktion str_glue() lassen sich Zeichenketten mit dem dynamischen Wert einer Variablen oder Funktion kombinieren. Dies kann beispielsweise bei Textelementen in Diagrammen eine nützliche Alternative zu paste() und paste0() sein.
Code anzeigen
str_glue("Der Datensatz «bgb_typ_clean_efz_eba» umfasst insgesamt", length(unique(bgb_typ_clean_efz_eba$region)), "Regionen", .sep =" ")
Der Datensatz «bgb_typ_clean_efz_eba» umfasst insgesamt 7 Regionen
Zeichenkette zwischen bestimmten Zeichen extrahieren
Die Funktion str_extract() extrahiert die erste Teilzeichenkette, die einem Regex-Muster entspricht. Sie verwendet Lookbehind (?<=\\[) und Lookahead (?=\\]), um Text zwischen [ und ] zu finden und einen einfachen Abgleich für Text zwischen ( und ) durchzuführen.
Code anzeigen
# Text zwischen eckigen Klammern extrahierenstr_extract(string = text, pattern ="(?<=\\[).*?(?=\\])") # Alternative: "\\[.*?\\]"
[1] NA
Code anzeigen
# Alle Übereinstimmungen extrahierenstr_extract_all(string = text, pattern ="(?<=\\[).*?(?=\\])|(?<=\\().*?(?=\\))")
[[1]]
[1] "EFZ"
Zeichenkette vor Leerzeichen extrahieren
Um den Teil der Zeichenkette vor dem ersten Leerzeichen zu finden und zu extrahieren, können Sie str_extract() mit einem regulären Ausdruck verwenden. Das Muster ^[^ ]+ entspricht dem Anfang der Zeichenkette (^), gefolgt von einem oder mehreren Zeichen, die keine Leerzeichen sind ([^ ]+).
Base R ist flexibel und benötigt keine zusätzlichen Pakete, aber die Syntax kann etwas umständlich sein.
stringr, Bestandteil von tidyverse, vereinfacht den Prozess mit intuitiven Funktionen, so dass der Code leichter zu lesen und zu schreiben ist.
stringi bietet leistungsfähige und effiziente String-Operationen, die sich für leistungskritische Aufgaben eignen.
Code anzeigen
zahlen <-str_extract_all(string = text, pattern ="\\d+") # \\d+ extrahiert eine oder mehrere Zahlenas.numeric(unlist(zahlen))
[1] 17888
Zahl in Ziffern aufteilen
Code anzeigen
# Funktion zum Aufteilen einer einzelnen Zahl in Ziffernsplit_number <-function(number){ number_str <-as.character(number) number_with_spaces <-gsub(pattern ="(.)", replacement ="\\1 ", # Leerzeichen zwischen den Ziffern einfügenx = number_str) digits <-strsplit(x = number_with_spaces, split =" ")[[1]]as.numeric(digits)}
Code anzeigen
# Funktion auf jede Zahl des Vektors anwendenlapply(X = zahlen, FUN = split_number)
[[1]]
[1] 1 7 8 8 8
Führende Nullen bei Zahlen hinzufügen
Manchmal ist es erforderlich, dass Zahlen ein bestimmtes Format haben. Das Hinzufügen von führenden Nullen ist eine Möglichkeit, die erforderliche Konsistenz der Datendarstellung zu gewährleisten.
# Zur Veranschaulichung wird der Begriff «Genferseeregion» durch zusätzlichen Text ergänztbgb_typ_clean_region <- bgb_typ_clean |>mutate(region =ifelse(region =="Genferseeregion", yes ="Region 1201 Genferseeregion", no = region)) |>filter(region =="Region 1201 Genferseeregion") |>pull(region)bgb_typ_clean_region
# case_when() ist eine Alternative zu ifelse(), insbesondere bei mehr als zwei Formelnbgb_typ_clean_region <-case_when(bgb_typ_clean$region =="Genferseeregion"~"Region 1201 Genferseeregion", bgb_typ_clean$region !="Genferseeregion"~ bgb_typ_clean$region)bgb_typ_clean_region[1:3]
Die Funktion sub() ersetzt die erste Übereinstimmung in einer Zeichenfolge durch neue Zeichen, während die Funktion gsub() alle Übereinstimmungen in einer Zeichenfolge durch neue Zeichen ersetzt.
Code anzeigen
# Erste Übereinstimmung ersetzenbgb_typ_clean_region |>sub(pattern ="region", replacement ="", ignore.case =TRUE)
# Alle Übereinstimmungen ersetzenbgb_typ_clean_region |># Für verschiedene Muster (pattern) den Operator | verwendengsub(pattern ="region", # Auch reguläre Ausdrücke möglich, z.B. ".*\\$" (bis/mit $-Zeichen)replacement ="", ignore.case =TRUE)
Eine einfache Methode ist auch die Verwendung der match()-Funktion von Base R.
Code anzeigen
# Daten für Beispiel aufbereitenlookup_tbl <-data.frame(gender =c("female", "male"), # Referenztabellecode =c("f", "m"))
Code anzeigen
# match() gibt die Pos. der ersten Übereinstimmung des ersten Arguments im zweiten Arg. zurückpenguins_df$gender_new <- lookup_tbl$code[match(x = penguins_def$sex, table = lookup_tbl$gender)]glue("Bisher: {penguins_df$sex[1]}, {penguins_df$sex[2]}, {penguins_df$sex[3]} Neu: {penguins_df$gender_new[1]}, {penguins_df$gender_new[2]}, {penguins_df$gender_new[3]}")
Bisher: male, female, female
Neu: m, f, f
Kontrollieren Sie die Daten stichprobenartig, nachdem Sie sie ersetzt haben.
Code anzeigen
table(penguins_df$gender_new, useNA ="ifany")
f m
165 168
map
Die Funktion map() erlaubt, verschiedene Textmanipulationen anzuwenden.
Code anzeigen
# Namen in Grossbuchstaben umwandelnmap(penguins_df$species, toupper) |>sample(size =5)
Ausreisser (engl. outlier) sind Werte, die eine signifikante Abweichung vom erwarteten Muster aufweisen. Ausreisser können durch natürliche Variabilität zustande kommen, aber auch auf einen experimentellen Fehler hindeuten. Ihre Identifizierung ist ein kritischer Schritt in der Datenanalyse, um statistische Ergebnisse nicht zu verfälschen und die Datenqualität zu sichern.
Mit der Funktion stats_dist() lassen sich die Verteilung und eine zusammenfassende Statistik für eine spezifische Spalte anzeigen.
Code anzeigen
# Standardthema für ggplot2-Plots festlegenggplot2::theme_set(theme_dv())
Eine häufig verwendete Regel zur Identifizierung von Ausreissern besagt, dass ein Wert ein Ausreisser ist, wenn er mehr als 1.5 x IQR über dem oberen Quartil (Q3) oder unter dem unteren Quartil (Q1) liegt. Mit anderen Worten, untere Ausreisser liegen unter Q1 - 1.5 x IQR und obere Ausreisser liegen über Q3 + 1.5 x IQR.
Der Z-Score bezieht sich auf die Anzahl der Standardabweichungen der einzelnen Datenwerte vom Mittelwert. Ein Z-Score von Null entspricht dem exakten Mittelwert. Ein üblicher Schwellenwert für die Identifizierung von Ausreissern ist ein Z-Score grösser als 3 oder kleiner als -3.
Code anzeigen
z_score <-scale(bgb_typ_clean$typ_eba)ausreisser <-abs(z_score) >3head(ausreisser, n =12)
Variablen können auf der Grundlage eines bestimmten Perzentils angepasst werden. Perzentile sind Lageparameter, die einen der Grösse nach geordneten Datensatz in 100 gleich grosse Teile zerlegen. Sie unterteilen den Datensatz also in 1%-Schritte.
Um sicherzustellen, dass keine wertvollen Informationen gelöscht werden, sollte das Entfernen eines bestimmten Perzentils der Daten sorgfältig geprüft werden.
Angenommen, Sie haben einen Datensatz und möchten den Mittelwert einer Variable verstehen. Wird dieser durch wenige Ausreisser verzerrt, ist der Aussagewert jedoch gering.
Bootstrapping ist eine statistische Technik, bei der mehrere Kopien der Daten erstellt werden, von denen jede eine leichte Abweichung aufweist. Die Statistik, die Sie interessiert (z.B. der Mittelwert), wird dann für jede Kopie berechnet.
Die Funktion bootstrap_stat_plot() berechnet und visualisiert die Verteilung, so dass Sie ein klares Bild davon erhalten, wie die Statistik zwischen den verschiedenen Versionen der Daten variiert. Detaillierte Infos zur Funktion finden Sie auf der dazugehörenden Website.
Die Korrelation ist ein statistisches Mass, das angibt, inwieweit zwei Variablen in einer linearen Beziehung zueinander stehen (d.h. sich in einem festen Verhältnis zueinander verändern).
Code anzeigen
# Metrisch skalierte Variablencor(x = penguins$bill_length_mm, y = penguins$bill_depth_mm, use ="complete.obs", method ="pearson") # Alternativen: Spearmans Rho und Kendalls Tau für ordinale Variablen
[1] -0.2350529
Code anzeigen
# Korrelationsmatrixcor(x = penguins[, 3:6], use ="complete.obs")
Unter der Voraussetzung einer Normalverteilung und der Annahme, dass es sich bei den vorliegenden Daten um eine Stichprobe aus einer Grundgesamtheit (Population) handelt, kann mit cor.test() die Signifikanz geprüft werden.
Code anzeigen
cor.test(x = penguins_def$bill_length_mm, y = penguins_def$bill_depth_mm, method ="pearson")
Pearson's product-moment correlation
data: penguins_def$bill_length_mm and penguins_def$bill_depth_mm
t = -4.2726, df = 331, p-value = 0.00002528
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
-0.3280409 -0.1242017
sample estimates:
cor
-0.2286256
In R können gruppierte Zusammenfassungen mit group_by() |> summarise() erstellt werden. group_by() ändert dabei die Analyseeinheit vom gesamten Datensatz zu einzelnen Gruppen. summarise() erstellt einen neuen Datenrahmen für die zusammenfassende Statistik.
# A tibble: 3 × 2
species Mittelwert_Gewicht
<fct> <dbl>
1 Gentoo 5092.
2 Chinstrap 3733.
3 Adelie 3706.
Angenommen, Sie haben viele numerische Spalten und möchten die Mittelwertfunktion auf alle Spalten anwenden. Mit across() ist es einfach, eine Funktion für mehrere Spalten zu verwenden.
Bei der Datenanalyse besteht oft die Notwendigkeit, die besten Werte innerhalb jeder Gruppe eines Datensatzes zu extrahieren. Unabhängig davon, ob es sich um Verkaufsdaten, Umfrageantworten oder eine andere Art von gruppierten Daten handelt, kann die Identifizierung der Top-Werte oder Ausreisser innerhalb jeder Gruppe wertvolle Erkenntnisse liefern.
Dank tabyl() aus dem Paket janitor können Prozent- und Absolutwerte zusammen ausgegeben werden. Mit adorn() lässt sich tabyl() zudem leicht anpassen. Sie können z.B. Summen hinzufügen oder die Anzahl der Nachkommastellen für Prozentwerte festlegen.
# A tibble: 4 × 3
species n percent
<fct> <dbl> <chr>
1 Adelie 146 43.8%
2 Chinstrap 68 20.4%
3 Gentoo 119 35.7%
4 Total 333 100.0%
Apply-Familie
Mit tapply() können Sie eine Funktion auf Untergruppen anwenden. Dies können in R vorhandene Funktionen wie mean() oder sd() sein, aber auch von Ihnen selbst geschriebene Funktionen.
Die Funktion tapply() kann auch zusammen mit summary() verwendet werden, um einen schnellen Überblick über die Verteilung einer Variable innerhalb von Gruppen zu erhalten.
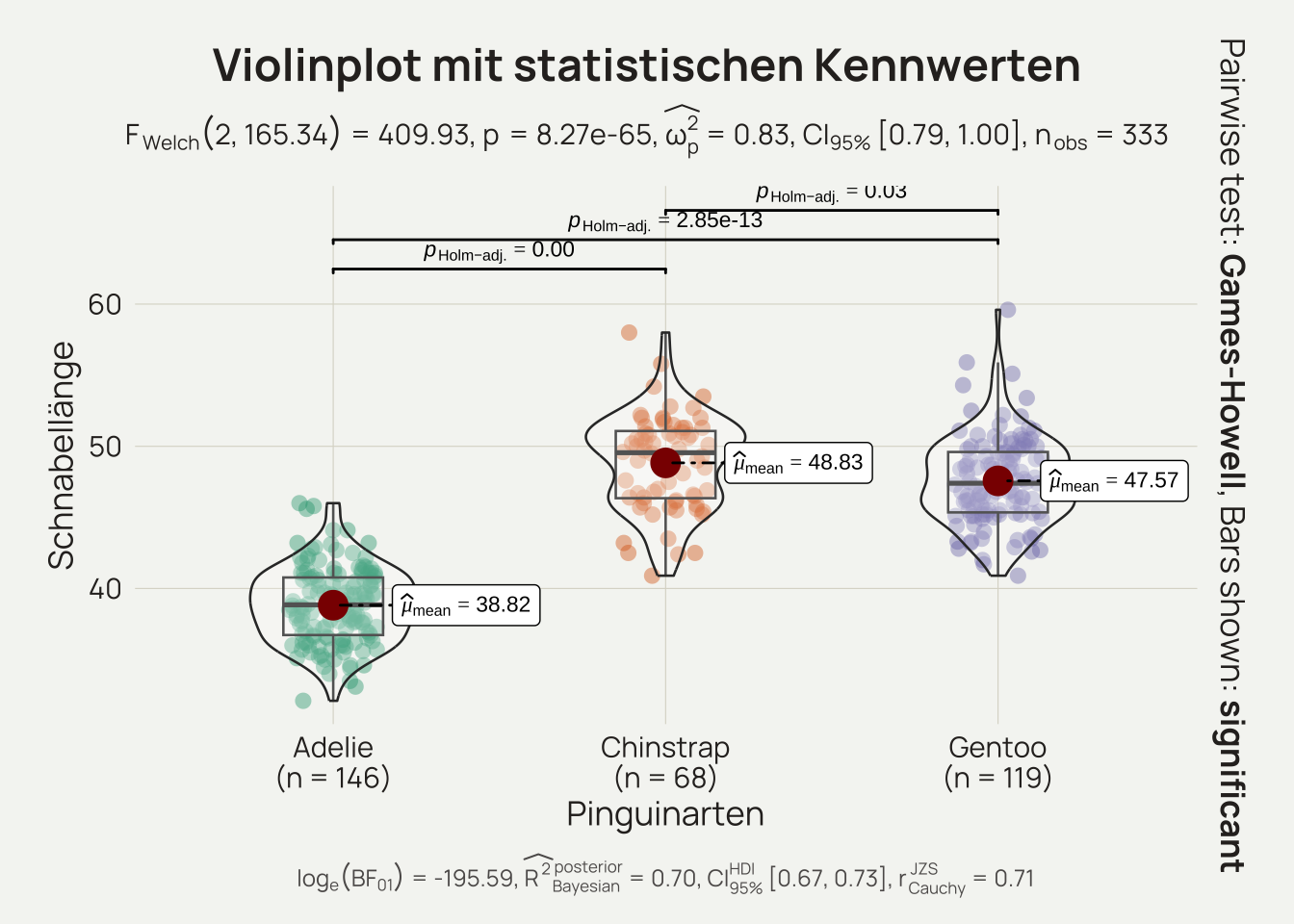
Code anzeigen
tapply(X = penguins_def$bill_length_mm, INDEX = penguins_def$species, FUN = summary, na.rm =TRUE) # Optional
$Adelie
Min. 1st Qu. Median Mean 3rd Qu. Max.
32.10 36.73 38.85 38.82 40.77 46.00
$Chinstrap
Min. 1st Qu. Median Mean 3rd Qu. Max.
40.90 46.35 49.55 48.83 51.08 58.00
$Gentoo
Min. 1st Qu. Median Mean 3rd Qu. Max.
40.90 45.35 47.40 47.57 49.60 59.60
Code anzeigen
schnabellaenge <-function(bill, avg_bill) { bill > avg_bill}# Pinguine finden, die einen längeren Schnabel haben als der Durchschnitttapply(X =head(penguins_def$bill_length_mm, n =15), INDEX =head(penguins_def$species, n =15), mean(penguins_def$bill_length_mm), FUN = schnabellaenge)
Die Funktion describeBy() aus dem psych-Paket berechnet verschiedene Kennwerte für jede Faktorstufe.
Code anzeigen
describeBy(x = penguins_def$bill_length_mm, penguins_def$species, mat =TRUE)
item group1 vars n mean sd median trimmed mad min max
X11 1 Adelie 1 146 38.82397 2.662597 38.85 38.77881 2.96520 32.1 46.0
X12 2 Chinstrap 1 68 48.83382 3.339256 49.55 48.90536 3.63237 40.9 58.0
X13 3 Gentoo 1 119 47.56807 3.106116 47.40 47.45155 3.11346 40.9 59.6
range skew kurtosis se
X11 13.9 0.15456020 -0.2197601 0.2203581
X12 17.1 -0.08661785 -0.1396985 0.4049443
X13 18.7 0.59674134 1.0696437 0.2847372
Numerische Variablen in Gruppen einteilen
Mithilfe von ntile() wird ein Eingabevektor in eine bestimmte Anzahl von Bereichen bzw. Rängen unterteilt.
Code anzeigen
# Pinguine in zwei Gewichtsgruppen einteilenpenguins_grouped <-ntile(x = penguins_def$body_mass_g, n =2)slice_head(.data =merge(x = penguins_grouped, y = penguins_def[, c(1, 2, 7)]), n =10) |>rename(gruppe = x)
gruppe species island sex
1 1 Adelie Torgersen male
2 1 Adelie Torgersen male
3 1 Adelie Torgersen male
4 1 Adelie Torgersen male
5 1 Adelie Torgersen male
6 1 Adelie Torgersen male
7 2 Adelie Torgersen male
8 1 Adelie Torgersen male
9 1 Adelie Torgersen male
10 2 Adelie Torgersen male
Numerische Variablen vergleichen
Um zwei numerische Variablen zu vergleichen, werden die Daten zunächst mit pivot_longer() in ein Langformat umgewandelt.
Code anzeigen
# Daten von breit nach lang transformierenpenguins_long <- penguins_def |>select(-c(bill_length_mm, bill_depth_mm, sex, year)) |>pivot_longer(cols = flipper_length_mm:body_mass_g, names_to ="variable", values_to ="wert")head(penguins_long, n =10)
options(scipen =999)penguins_long |>group_by(species, variable) |>summarise(summe_lv =sum(wert), .groups ="keep") |>ggplot() +geom_bar(mapping =aes(x = species, y = summe_lv, fill = variable), alpha =0.7, stat ="identity", position =position_dodge(width =0.9)) +scale_y_continuous(labels =comma_format(big.mark ="'")) +scale_fill_paletteer_d(palette ="nbapalettes::pacers_classic", labels =c("Gewicht", "Flossenlänge")) +labs(title ="Pinguine im Vergleich", x ="Pinguinarten", y ="Wert") +theme_minimal(base_size =10) +theme_dv(axis.text.x =element_text(angle =90, hjust =1), panel.grid.major.y =element_line(color ="#5D5A59", linetype ="dashed", linewidth =0.5)) +theme(legend.title =element_blank())
Numerische Variablen normalisieren
Wenn die Werte, wie im obigen Beispiel, auf unterschiedlichen Skalen liegen, sind sie nicht ohne weiteres vergleichbar. Eine gebräuchliche Technik im Umgang mit numerischen Daten besteht darin, diese so zu normalisieren, dass die Werte ihre proportionale Verteilung behalten, aber auf derselben Skala gemessen werden. Zu diesem Zweck wird eine Technik namens Min/Max-Skalierung verwendet, bei der die Werte proportional auf einer Skala von 0 bis 1 verteilt werden.
Code anzeigen
# group_by() stellt sicher, dass die Variablen unabhängig voneinander normalisiert werden.penguins_normalized <- penguins_long |>group_by(variable) |>mutate(wert =rescale(wert, to =c(0, 1)))head(penguins_normalized)
Alternativ können numerische Variablen im Datensatz mit der Funktion scale() normalisiert werden. Jede Variable wird so standardisiert, dass sie einen Mittelwert von 0 und eine Standardabweichung von 1 hat.
Vergleichen Sie die numerischen Variablen erneut in einem Balkendiagramm. Diesmal wird jedoch der Datensatz mit den normalisierten Werten verwendet.
Code anzeigen
options(scipen =999)penguins_normalized |>group_by(species, variable) |>summarise(summe_lv =sum(wert), .groups ="keep") |>ggplot() +geom_bar(mapping =aes(x = species, y = summe_lv, fill = variable), alpha =0.7, stat ="identity", position =position_dodge(width =0.9)) +scale_fill_paletteer_d(palette ="nbapalettes::pacers_classic", labels =c("Gewicht", "Flossenlänge")) +labs(title ="Pinguine im Vergleich", x ="Pinguinarten", y ="Wert") +theme_minimal(base_size =10) +theme_dv(axis.text.x =element_text(angle =90, hjust =1), panel.grid.major.y =element_line(color ="#5D5A59", linetype ="dashed", linewidth =0.5)) +theme(legend.title =element_blank())
Daten exportieren
In R bearbeitete Datensätze können in verschiedenen Formaten exportiert werden, um sie in anderen Anwendungen weiterzuverwenden. Beispielsweise kann das Paket writexl() Datensätze im Excel-Format speichern.
Datenvisualisierung
Bedeutung
Die Visualisierung von Daten ist eine effiziente Methode, neues Wissen zu entdecken und dieses Nicht-Experten mit Hilfe visueller Darstellungen auf eine zugängliche Weise zu vermitteln.
ggplot2
ggplot2 ist ein Paket zur Erstellung eleganter Datenvisualisierungen in R.
Eine Visualisierung initialisieren Sie mit der Funktion ggplot() und dem Datensatz, der für die Darstellung verwendet werden soll. ggplot(data = df) erstellt im Grunde ein leeres Diagramm, dem Sie mittels Pluszeichen (+) Ebenen hinzufügen können.
geom_col() fügt dann eine Ebene von Balken hinzu, deren Höhe den Variablen entspricht, die durch das Mapping-Argument angegeben sind. Das Argument mapping ist immer mit aes() gekoppelt, das bestimmt, wie die Variablen auf der X- und Y-Achse abgebildet werden.
Mehrere Plots zusammen ausgeben
Mit der Funktion par() lassen sich mehrere Plots nebeneinander ausgegeben. Dies ist hilfreich, wenn man beispielsweise die Verteilung mehrerer Variablen vergleichen möchte.
Code anzeigen
# Ausgabe der Ergebnisse in wissenschaftlicher Notation deaktivierenoptions(scipen =999)
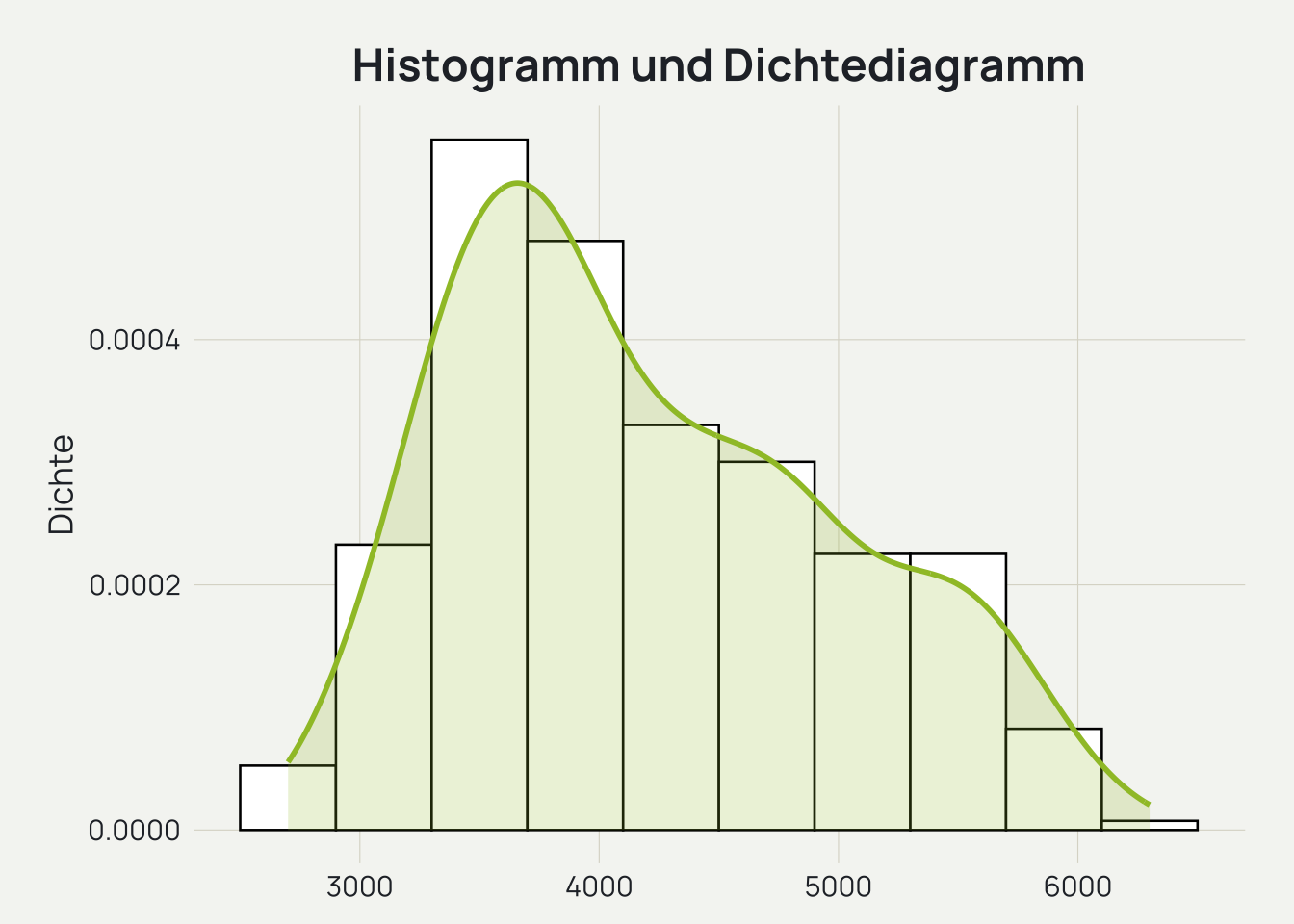
penguins_def |>ggplot(mapping =aes(x = body_mass_g)) +geom_histogram(mapping =aes(y =after_stat(density)), bins =10, color ="black", fill ="white") +geom_density(color ="#9FC131", fill ="#9FC131", linewidth =1, alpha =0.2) +labs(title ="Histogramm und Dichtediagramm", x =NULL, y ="Dichte") +theme_minimal(base_size =10) +theme_dv()
Säulendiagramm
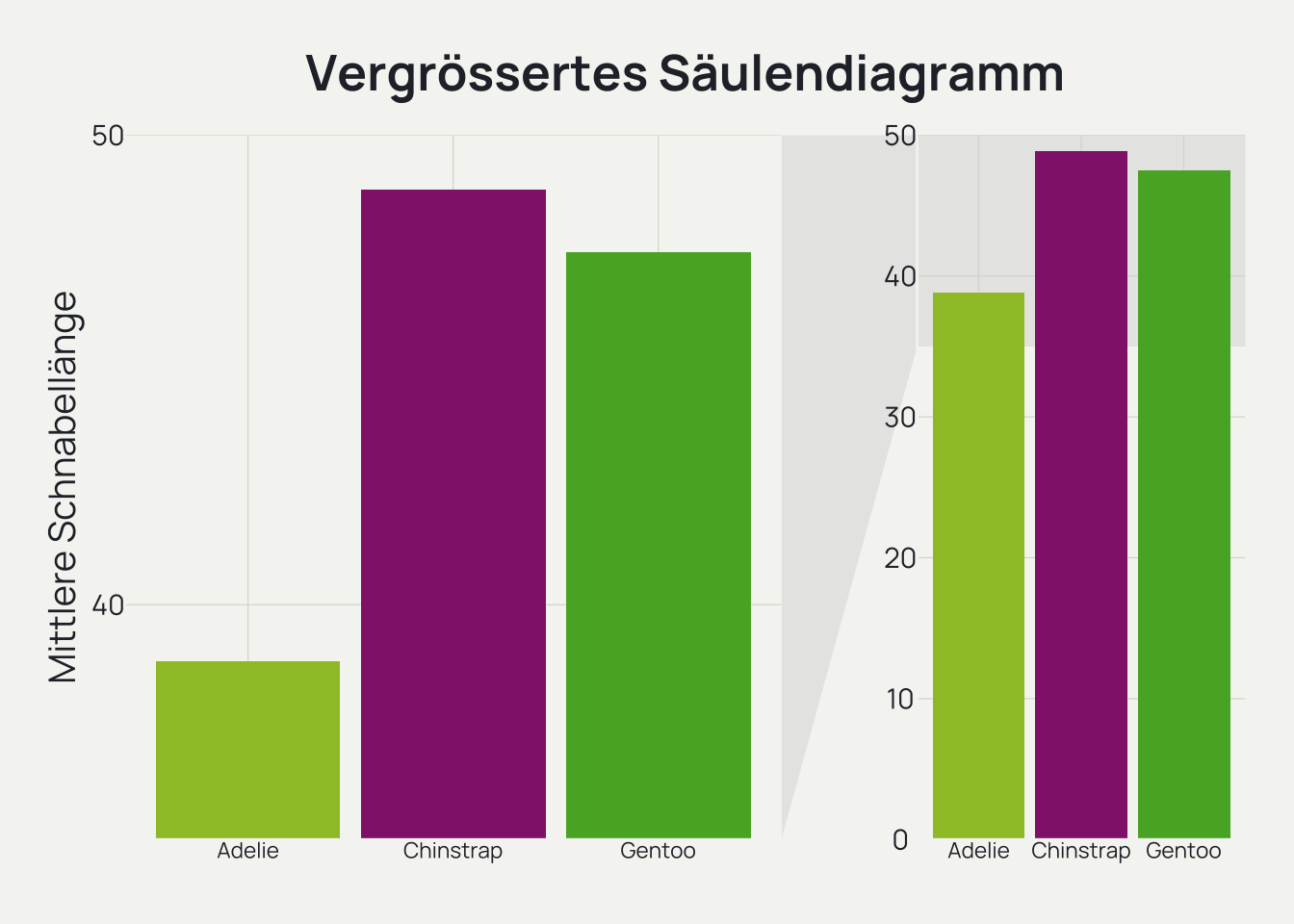
Vergrössertes Säulendiagramm
Wenn kleine Abweichungen im Säulendiagramm von Bedeutung sind, ist es empfehlenswert, beides darzustellen. Ein normales Säulendiagramm, das bei Null beginnt, aber auch eine vergrösserte Version, die es dem Leser ermöglicht, die einzelnen Säulenwerte besser zu erkennen. Das folgende Beispiel zeigt das normale Säulendiagramm auf der rechten Seite und eine vergrösserte Version, die einen Teil der Achse zeigt, auf der linken Seite. Die Verbindungslinien zwischen den beiden Versionen zeigen, auf welchen Datenbereich sich die abgeschnittene Achse bezieht.
Ähnlich kann verfahren werden, wenn eine Säule viel länger ist als die anderen, so dass es schwierig ist, alle kleinen Säulen zu unterscheiden.
Code anzeigen
# Daten für Beispiel aufbereitenmittlere_schnabellaenge_df <-as.data.frame(mittlere_schnabellaenge) |>rownames_to_column()colnames(mittlere_schnabellaenge_df) <-c("species", "mean_bill_length_mm")
Für die Darstellung von Diagrammen kann in R eine eigene Farbpalette definiert werden.
mittlere_schnabellaenge_df |>ggplot(mapping =aes(x = species, y = mean_bill_length_mm, fill = species)) +geom_col() +facet_zoom(ylim =c(35, 50)) +scale_fill_manual(values = palette) +scale_y_continuous(breaks =seq(0, 50, by =10), labels =seq(0, 50, by =10), limits =c(0, 50), expand =c(0, 0)) +labs(title ="Vergrössertes Säulendiagramm", x ="", y ="Mittlere Schnabellänge") +theme_dv(legend.position ="none") +theme(axis.text.x =element_text(size =rel(0.7)), axis.text.y =element_text(size =rel(0.9)), plot.title =element_text(margin =margin(t =0, r =0, b =15, l =0, unit ="pt")))
Verschachteltes Säulendiagramm
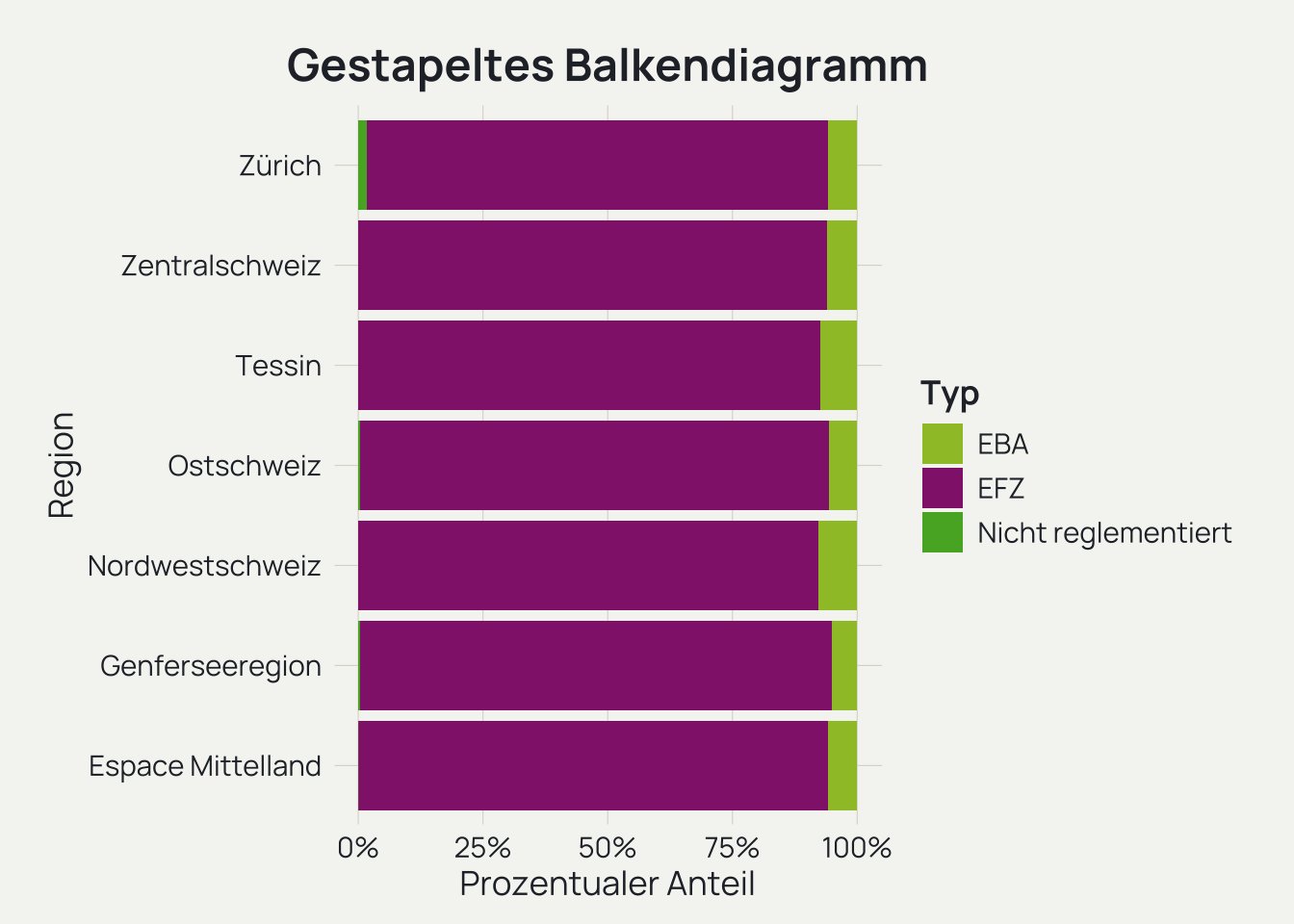
Gestapelte Säulen- und Flächendiagramme erschweren den Vergleich von Untergruppen, da eine gemeinsame Basislinie fehlt. Ein gruppiertes Säulendiagramm löst dieses Problem teilweise, indem die Säulen nebeneinander statt übereinander angeordnet werden. Auf diese Weise sind die Untergruppen leicht zu vergleichen, aber die Gesamtsumme jeder Gruppe ist sehr schwer zu erfassen oder muss im Kopf addiert werden. Das verschachtelte Säulendiagramm ermöglicht es, sowohl die Untergruppen als auch die Gesamtzahl auf einen Blick zu vergleichen.
Code anzeigen
# Daten für Beispiel aufbereitenbgb_typ_clean_stacked <- bgb_typ_clean |>select(starts_with("typ"), region) |>pivot_longer(cols =!region, names_to ="typ", values_to ="wert")bgb_typ_clean_stacked$typ[bgb_typ_clean_stacked$typ =="typ_nicht_bbg_reglementierte_berufliche_grundbildung"] <-"typ_nicht_reglementiert"
`summarise()` has regrouped the output.
ℹ Summaries were computed grouped by region and typ.
ℹ Output is grouped by region.
ℹ Use `summarise(.groups = "drop_last")` to silence this message.
ℹ Use `summarise(.by = c(region, typ))` for per-operation grouping
(`?dplyr::dplyr_by`) instead.
Code anzeigen
# Summe der Lehrverträge pro Region für graue Balken berechnenregion_totals <- bgb_typ_clean_stacked |>group_by(region) |>summarise(total =sum(wert, na.rm =TRUE), .groups ="drop") # Probleme mit gruppiertem Datenrahmen vermeiden
# Ebene 1: Summe der Lehrverträge pro Region für Säulen im Hintergrund erstellenggplot() +geom_col(data = region_totals, mapping =aes(x = region, y = total), width =0.8, fill ="grey85", # Hellgraue Füllungalpha =0.8) +# Ebene 2: Säulen nebeneinander anordnengeom_col(data = bgb_typ_clean_stacked_grouped, mapping =aes(x = region, y = wert, fill = typ), position =position_dodge(width =0.8), width =0.7) +# Säulen etwas schmaler gestalten als graue Säulen im Hintergrund# Ebene 3: Labels für einzelne Typensäulengeom_text(data = bgb_typ_clean_stacked_grouped, mapping =aes(x = region, y = wert, label = wert, group = typ), position =position_dodge(width =0.8), size =2.5, # Textgrösse anpassenvjust =-0.5, # Label über der Säule positionierenfamily ="Manrope") +# Ebene 4: Labels für die gesamte Regiongeom_text(data = region_totals, mapping =aes(x = region, y = total, label = total), size =3, vjust =-2.0, # Position über der grauen Säule, vertikale Position anpassenfamily ="Manrope") +# Ebene 5: Labels für Regionsnamengeom_text(data = region_totals, mapping =aes(x = region, y = total, label =as.character(region)), # Label muss Character seinsize =3, vjust =-3.5, # Position über dem Label mit den Gesamtwertenfamily ="Manrope", fontface ="bold") +# Benutzerdefinierte Farbskala anwenden und Titel festlegenscale_fill_manual(labels =c("EBA", "EFZ", "Nicht reglementiert"), values = palette) +labs(title ="Verschachteltes Säulendiagramm") +# Theme anpassentheme_minimal(base_size =10) +theme_dv(legend.key.size =unit(x =0.5, units ="cm"), legend.margin =margin(b =-10), legend.position ="top", ) +theme(axis.title =element_blank(), axis.text =element_blank(), legend.text =element_text(size =rel(0.9)), legend.title =element_blank(), panel.grid.major =element_blank(), plot.title =element_text(margin =margin(b =12)) ) +# Platz für Beschriftungen über grauen Säulen schaffenscale_y_continuous(limits =c(0, max(region_totals$total) *1.25), # Oben ca. 25% zus. Platz expand =expansion(mult =c(0, 0))) # Y-Achse bei 0 beginnen
Balkendiagramm
Gestapeltes Balkendiagramm
Ein gestapeltes Balkendiagramm wird verwendet, um die kumulierten Prozentsätze pro Gruppe anzuzeigen.
Code anzeigen
bgb_typ_clean_stacked |>na.omit() |>ggplot(mapping =aes(x =factor(region), y = wert, fill =factor(typ))) +geom_bar(stat ="identity", position ="fill") +scale_fill_manual(labels =c("EBA", "EFZ", "Nicht reglementiert"), values = palette, na.value ="#5D5A59") +scale_y_continuous(labels = scales::percent_format()) +labs(title ="Gestapeltes Balkendiagramm", x ="Region", y ="Prozentualer Anteil", fill ="Typ") +theme_minimal(base_size =10) +theme_dv() +coord_flip()
Dichteplot
In der Statistik geht es oft darum, Stichproben von Daten zu nehmen und mithilfe von Wahrscheinlichkeitsfunktionen Informationen über die gesamte Datenpopulation (Grundgesamtheit) zu extrapolieren. Mit einer ausreichenden Anzahl dieser Zufallsvariablen können Sie eine sogenannte Wahrscheinlichkeitsdichtefunktion berechnen, welche die Verteilung der Variable für die gesamte Population schätzt.
Ein Dichteplot ist eine Darstellung der Verteilung einer numerischen Variable. Es handelt sich um eine geglättete Version des Histogramms und wird häufig in der gleichen Situation verwendet. geom_density() berechnet und zeichnet eine solche Kernel-Dichte-Schätzung.
Ein Boxplot fasst die Verteilung einer numerischen Variablen in einer oder mehreren Gruppen zusammen und ist daher ein praktisches Werkzeug, um Unterschiede zwischen diesen Gruppen schnell zu erfassen. Diese Zusammenfassung kann jedoch auch dazu führen, dass wichtige Informationen verloren gehen, was ein potenzieller Stolperstein sein kann. Wenn die Datenmenge, mit der Sie arbeiten, nicht zu gross ist, kann das Hinzufügen von Jitter zu Ihrem Boxplot das Diagramm aussagekräftiger machen.
Code anzeigen
penguins_group <- penguins_def |>group_by(species) |>summarise(num =n())penguins_def |>left_join(y = penguins_group, by =join_by(species)) |>mutate(myaxis =paste0(species, "\n", "n = ", num)) |>ggplot(mapping =aes(x = myaxis, y = body_mass_g)) +geom_boxplot() +geom_jitter(colour ="grey", size =1.1, alpha =0.6) +labs(title ="Boxplot mit Jitter", x ="Pinguinarten", y ="Wert") +theme_minimal(base_size =10) +theme_dv(legend.position ="none")
Boxplot mit Streudiagramm
Code anzeigen
penguins_def |>ggplot(mapping =aes(x = body_mass_g, y =1)) +stat_dist_halfeye(fill ="#93257B") +geom_point(mapping =aes(y =0.75), shape =21, colour ="#9FC131", size =4, fill ="#9FC131", alpha =0.7, position =position_jitter(height =0.1, seed =1234)) +geom_boxplot(width =0.25, colour ="black", linewidth =1) +labs(title ="Boxplot mit Streudiagramm", x ="Wert", y =element_blank()) +theme_minimal(base_size =10) +theme_dv(legend.position ="none", panel.grid.major.y =element_blank()) +coord_cartesian(xlim =range(penguins_def$body_mass_g))
Warning: `label` cannot be a <ggplot2::element_blank> object.
Regenwolkenplot
Das Regenwolkendiagramm ist eine Kombination aus Boxplot und Violinplot mit einem Histogramm zur detaillierten Darstellung der Daten.
Code anzeigen
penguins_def |>ggplot(mapping =aes(x = body_mass_g, y =1)) +stat_halfeye(fill ="#93257B") +stat_dots(mapping =aes(y =0.8), colour ="#9FC131", fill ="#9FC131", side ="bottom") +geom_boxplot(width =0.25, colour ="black", linewidth =1) +labs(title ="Regenwolkenplot", x ="Wert", y =element_blank()) +theme_minimal(base_size =10) +theme_dv(legend.position ="none", panel.grid.major.y =element_blank()) +coord_cartesian(xlim =range(penguins_def$body_mass_g))
Warning: `label` cannot be a <ggplot2::element_blank> object.
Violinplot
Violinplot mit statistischen Kennwerten
Ein Violinplot (manchmal auch als Geigenplot bezeichnet) ist eine Art der Datenvisualisierung, die einen Boxplot und ein Kerndichtediagramm kombiniert, um die Verteilung einer numerischen Variablen über verschiedene Gruppen oder Kategorien darzustellen. Er kann dabei helfen, Form, Verteilung und Ausreisser der Daten zu vergleichen und multimodale Muster zu identifizieren.
Code anzeigen
penguins_def |>ggbetweenstats(x = species, y = bill_length_mm) +labs(title ="Violinplot mit statistischen Kennwerten", x ="Pinguinarten", y ="Schnabellänge") +theme_minimal(base_size =10) +theme_dv(legend.position ="none", plot.title.position ="plot") +theme(plot.subtitle =element_text(size =rel(1.1), margin =margin(t =0, r =0, b =8, l =0, unit ="pt")))
Streudiagramm
Symmetrisches Streudiagramm
Bei der Darstellung der Residuen eines linearen Regressionsmodells wird u. a. darauf geachtet, wie die Punkte um die Nulllinie verteilt sind. Bei Residuendiagrammen führen die Standardeinstellungen oft zu einer y-Achse, die nicht symmetrisch um 0 ist. Dies kann die Vergleichbarkeit erschweren. Wenn die y-Achse symmetrisch um den Nullpunkt gelegt und eine Nulllinie hinzugefügt wird, ist es einfacher zu erkennen, ob mehr Punkte über oder unter dem Nullpunkt liegen.
Code anzeigen
# Daten für Beispiel aufbereitenpenguins_adelie <- penguins_def |>filter(species =="Adelie")# Modell erstellenfit <-lm(formula = body_mass_g ~ bill_length_mm, data = penguins_adelie)fit_df <- broom::augment(fit)
Code anzeigen
fit_df |>ggplot(mapping =aes(x = .fitted, y = .resid)) +geom_point() +geom_hline(yintercept =0, colour ="#9FC131") +scale_y_continuous(limits =c(-1200, 1200), expand =c(0, 0)) +labs(title ="Symmetrisches Streudiagramm", x ="", y ="") +theme_minimal(base_size =10) +theme_dv()
Streudiagramm mit Quantilsanzeige
Das Quantil kann für den ausgewählten Datensatz und die Variable flexibel gewählt werden.
Warning: `label` cannot be a <ggplot2::element_blank> object.
Vergleichen leicht gemacht
Beim Vergleichen mehrerer Gruppen lassen sich zwar einzelne Trends erkennen, doch kann es schwierig sein, die Werte korrekt in das Gesamtbild einzuordnen. Eine einfache Lösung besteht darin, den vollständigen Datensatz als schattierte Hintergrundebene zu jedem Diagramm hinzuzufügen, um einen Kontext für Vergleiche zu schaffen.
Code anzeigen
penguins_def |>ggplot(mapping =aes(x = bill_length_mm, y = bill_depth_mm)) +# Spalte "species" entfernen, um Teilmenge zu vermeidengeom_point(data =select(.data = penguins_def, -species), mapping =aes(size = body_mass_g), colour ="grey85", alpha =0.7) +geom_point(mapping =aes(fill = species, size = body_mass_g), shape =21, alpha =0.7) +facet_wrap(facets =vars(species)) +scale_fill_manual(values = palette) +scale_size_area(max_size =5) +labs(title ="Streudiagramm mit Facetten", x ="Schnabellänge",y ="Schnabeltiefe") +theme_minimal(base_size =10) +theme_dv(legend.position ="none") +theme(# Abstände zwischen Panels vergrössernpanel.spacing.x =unit(x =30, units ="pt") )
Streudiagramm für Teilmengen
Mithilfe der Funktion nest_by() lassen sich Diagramme über Teilmengen hinweg erstellen und zur späteren Verwendung in einem Datenrahmen speichern. Geschweifte Klammern helfen dabei, Umgebungsvariablen von Data Frame-Variablen innerhalb einer Funktion zu unterscheiden, in der Data Frame-Variablen aus der Umgebung übergeben werden.
Code anzeigen
# Hilfsfunktion zur Erstellung der Streudiagrammescatter_fn <-function(df, col1, col2, title) { df |>ggplot(mapping =aes(x = {{ col1 }}, y = {{ col2 }})) +geom_point() +geom_smooth(method ="lm", formula ="y ~ x") +labs(title = title, x ="Schnabellänge",y ="Schnabeltiefe") +theme_minimal(base_size =10) +theme_dv()}
Code anzeigen
# Pinguine nach Arten gruppieren und eine Listenspalte mit Plot-Objekten hinzufügenpenguin_scatter <- penguins_def |>nest_by(species) |>mutate(plot =list(scatter_fn(df = data, col1 = bill_length_mm, col2 = bill_depth_mm, title = species)))
Rows: 3
Columns: 3
Rowwise: species
$ species <fct> Adelie, Chinstrap, Gentoo
$ data <list<tibble[,7]>> [<tbl_df[146 x 7]>], [<tbl_df[68 x 7]>], [<tbl_df[119 x 7]>]…
$ plot <list> <ggplot2::ggplot>, <ggplot2::ggplot>, <ggplot2::ggplot>
Code anzeigen
for (i in1:3) {assign( # Weist einem Namen in der Umgebung einen Wert zux =paste("plot", i, sep ="_"),value = penguin_scatter$plot[i][[1]] )}
Ein Randdiagramm ist ein Streudiagramm mit Histogrammen, Boxplots oder Dichtediagrammen an den Rändern der x- und y-Achse. Es ermöglicht die Untersuchung der Beziehung zwischen zwei numerischen Variablen. Die Randdiagramme werden in der Regel am oberen und rechten Rand des Basisdiagramms dargestellt und zeigen die Verteilung der Variablen. Dies hilft, die Verteilung für verschiedene Variablenwerte entlang der beiden Achsen zu visualisieren.
Code anzeigen
plot <- penguins_def |>ggplot(mapping =aes(x = bill_depth_mm, y = bill_length_mm)) +geom_point() +labs(title ="Randdiagramm", subtitle ="Streudiagramm mit Histogramm", x ="Schnabeltiefe", y ="Schnabellänge") +theme_minimal(base_size =10) +theme_dv(legend.position ="none") +theme(text =element_text(family ="Helvetica"), plot.subtitle =element_text(margin =margin(t =0, r =0, b =8, l =0, unit ="pt")))
Code anzeigen
ggExtra::ggMarginal(p = plot, type ="histogram", size =10, colour =NA, fill ="#9FC131")
Die alternative Darstellung des Randdiagramms unten wurde mit dem Paket patchwork erstellt.
# Streudiagramm und beide Histogramme mit patchwork kombinierenp2 +plot_spacer() + p1 + p3 +plot_layout(widths =c(4, 1), heights =c(1, 4))
Treemap
Eine Treemap stellt hierarchische Daten als eine Reihe von verschachtelten Rechtecken dar. Jede Gruppe wird durch ein Rechteck dargestellt, dessen Fläche proportional zu ihrem Wert ist.
`summarise()` has regrouped the output.
ℹ Summaries were computed grouped by island and species.
ℹ Output is grouped by island.
ℹ Use `summarise(.groups = "drop_last")` to silence this message.
ℹ Use `summarise(.by = c(island, species))` for per-operation grouping
(`?dplyr::dplyr_by`) instead.
Multidimensionale Skalierung
Die Visualisierung von Ähnlichkeiten zwischen Datenpunkten kann schwierig sein, insbesondere wenn es sich um viele Merkmale handelt. Hier kommt die multidimensionale Skalierung (MDS) ins Spiel. Sie ermöglicht die Untersuchung dieser Beziehungen in einem niedrigdimensionalen Raum, typischerweise 2D oder 3D, um die Interpretation zu erleichtern.
Code anzeigen
# Relevante numerische Merkmale auswählen (für eine bestimmte Anzahl Zeilen)mds_features <- penguins_def[11:20, c(3:6)]# Paarweise Abstände zwischen Merkmalen berechnenmds_matrix <-dist(mds_features)# head(mds_matrix)
Code anzeigen
# MDS durchführen, um eine 2D-Darstellung zu erhaltenmds_results <-cmdscale(d = mds_matrix, k =2)# head(mds_results, n = 3)
Code anzeigen
# R-Basisplot erstellenplot(x = mds_results[, 1], y = mds_results[, 2], main ="Multidimensionale Skalierung für Pinguine", xlab ="Dimension 1", ylab ="Dimension 2")# Textbeschriftungen hinzufügen (optional)text(mds_results, labels = penguins_def$species, col ="#9FC131", cex =0.62, pos =1)
Warning in text.default(mds_results, labels = penguins_def$species, col = "#9FC131", : length(labels) > max(length(x), length(y));
'labels' truncated to length 10
Dynamische Grafiken
Ergänzend zu den statischen Datenvisualisierungen mit plot() oder ggplot2 gibt es für R verschiedene Pakete, mit denen Sie interaktive und dynamische Grafiken erstellen können.
Ob für Berichte, Präsentationen oder wissenschaftliche Arbeiten, gt ermöglicht die Erstellung optisch ansprechender Tabellen mit detaillierter Kontrolle über die Formatierung und ist damit ein unverzichtbares Werkzeug für die professionelle Präsentation Ihrer Daten.
reactable
Das reactable-Paket basiert auf der JavaScript-Bibliothek «React Table» und ist ein flexibles Werkzeug zur Erstellung interaktiver und anpassbarer Tabellen in Webanwendungen und R Shiny Dashboards.
Abschliessende Worte
Fazit
Durch die Verwendung der sechs Verben (filtern, anordnen, auswählen, mutieren, gruppieren und zusammenfassen), die Sie in dieser Anleitung gelernt haben, sind Sie auf dem besten Weg, die meisten Herausforderungen bei der Datenanalyse in R zu lösen. Datenvisualisierungen mit ggplot2 erleichtern zudem das Erkennen komplexer Zusammenhänge während der Datenanalyse und schaffen Klarheit bei der Präsentation vor dem Auftraggeber.
Ausblick auf Machine Learning
Prolog
Maschinelles Lernen wird in R mit dem Paket caret oder dem tidymodels-Framework (https://www.tidymodels.org) realisiert. Ein einfacher Ansatz für maschinelles Lernen (ML) ist z.B. die Erstellung eines linearen Regressionsmodells mit der Funktion lm().
tidyAML
tidyAML ist ein R-Paket, das es ermöglicht, das tidymodels-Ökosystem zu nutzen, um automatisiertes maschinelles Lernen (AutoML) durchzuführen, insbesondere wenn keine Feinabstimmung erforderlich ist. Mit tidyAML können Benutzer viele hochwertige maschinelle Lernmodelle und Vorhersagen auf einmal erstellen. Ein Sicherheitsmechanismus stellt sicher, dass das Paket korrekt fehlschlägt, wenn die erforderlichen Erweiterungspakete nicht installiert sind.
Es ist möglich, die gewünschten Modelle auszuwählen, indem man entweder die unterstützten Parsnip-Funktionen wie linear_reg() oder die gewünschte Engine auswählt; man kann auch beide zusammen verwenden.
Die Funktion fast_regression() verwendet Ihre Daten und das Rezeptobjekt, um mehrere Regressionsmodelle mit einer Vielzahl von Engines und Funktionen aus dem Paket parsnip zu generieren.
Mit der Funktion extract_regression_residuals() lassen sich die Residuen der angepassten Modelle zusammen mit den ursprünglichen und den vorhergesagten Daten extrahieren.
Die Qualität der Modelle kann durch Visualisierung mit den beiden Funktionen plot_regression_residuals() und plot_regression_predictions() überprüft werden. Damit können die Residuen sowie ein Vergleich zwischen Vorhersage und Wirklichkeit dargestellt und mögliche Probleme identifiziert werden.